



Launching Databricks at If Insurance | Medium
April 24, 2021
1 min
Despite the progress in data science and cloud data platforms, many data teams still struggle with data pipelines.
In software engineering, practices like unit testing, integration testing, continuous integration, continuous deployment, are considered as vital techniques.
Unfortunately, data pipeline projects, often fall way behind. Due to poor tools support, lack of experience, or “that’s how we build ETL pipelines” mindset, data pipelines are closer to cowboy coding rather than software craftsmanship.
P.s. Committing your code to a git repository doesn’t yet mean it’s a full-blown DevOps setup.
Lately, I’ve been experimenting with Data Build Tool, I wrote an article how to get started with it. And now, I’ve prepared a short demo of it.
Data pipeline is the foundation behind high quality golden data products. In this blog post, I give a quick overview and a demo of data pipeline development with Data Build Tool (DBT), Databricks, Delta Lake, Azure Data Lake and Azure DevOps.
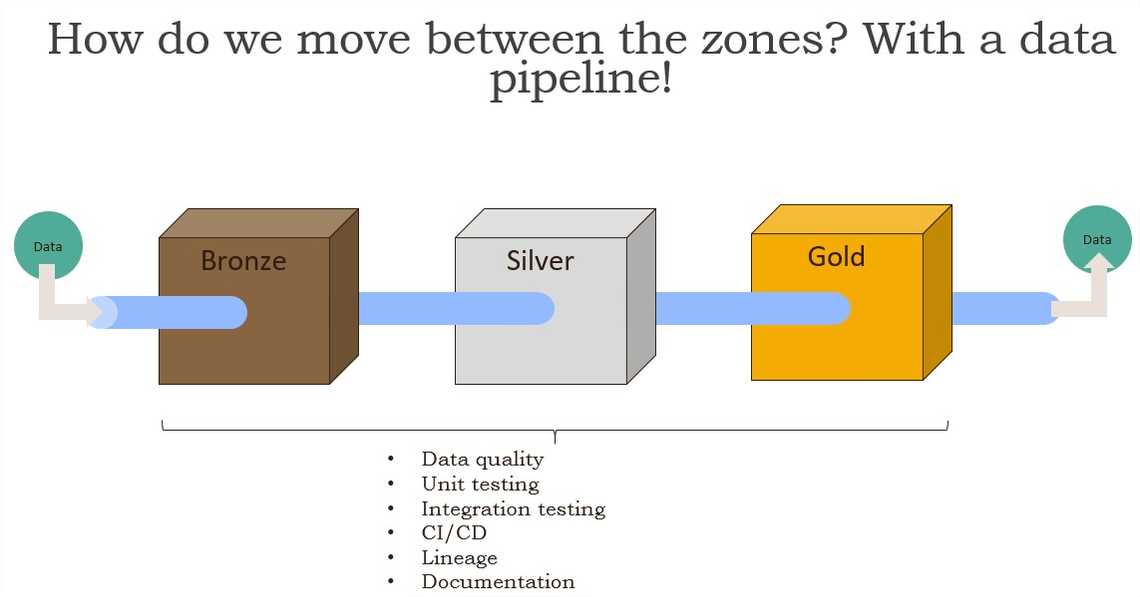
From enterprise architecture view, any capability needs three components: people, tools and process. In data pipeline context, it might look something like this:
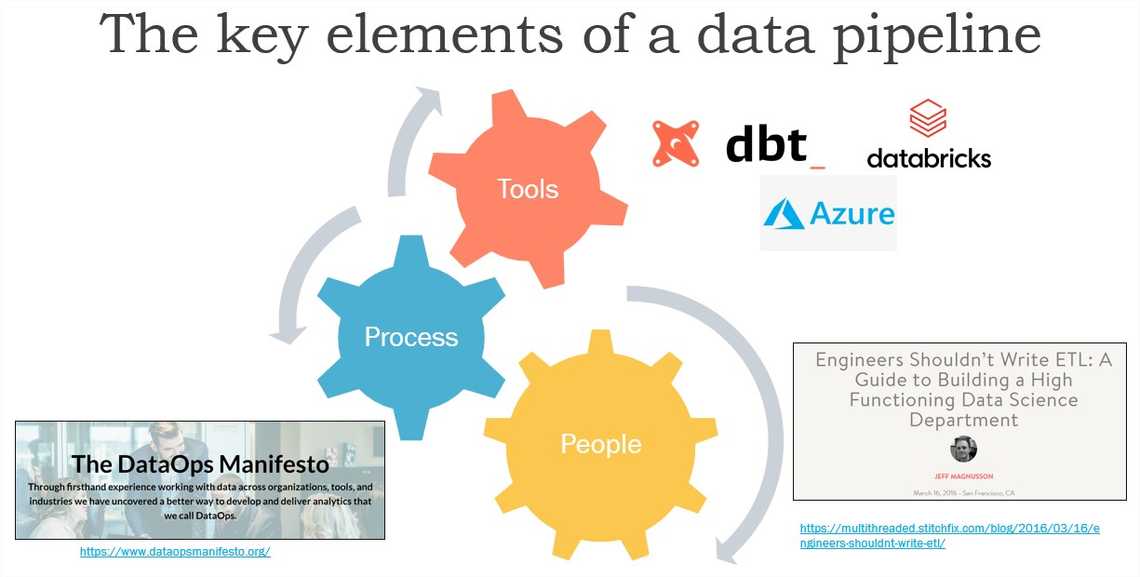
Links: https://www.dataopsmanifesto.org/ and https://multithreaded.stitchfix.com/blog/2016/03/16/engineers-shouldnt-write-etl/
However, at the end of the day, the architecture is way more complex, and here is a more detail view on different components required for having data pipelines in Databricks and Delta Lake.
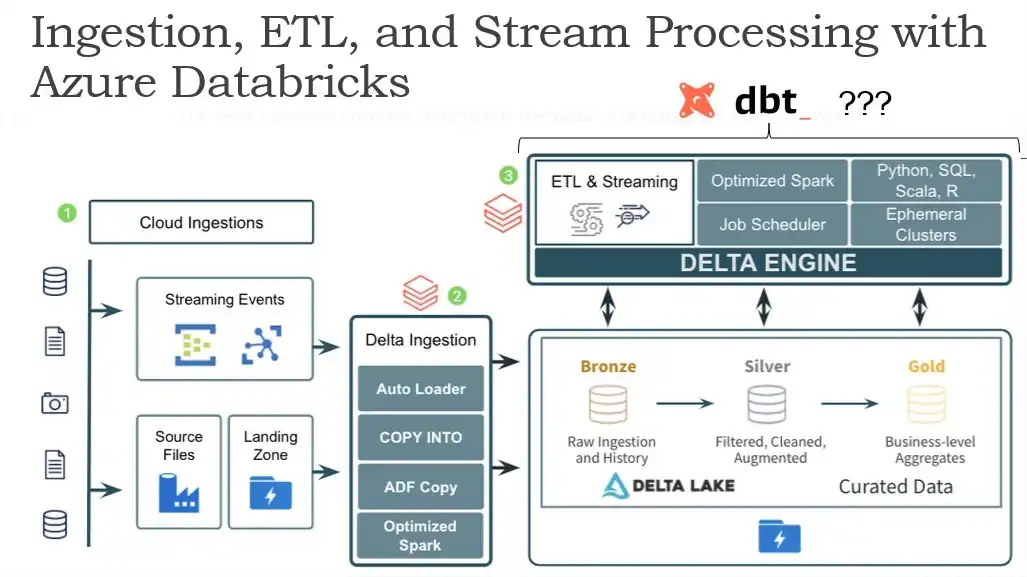
Original source: https://techcommunity.microsof…

I’ve prepared a video where I go through dbt development in Visual Studio Code, using Databricks as a target compute, and finally, using Azure DevOps pipelines for deployment
Watch full recording below:
Link to GitHub repository: https://github.com/valdasm/dbt-databricks-demo
Other projects