



Launching Databricks at If Insurance | Medium
April 24, 2021
1 min
Azure Data Lakehouse architecture combines the best elements of data lakes and data warehouses. Delta file format, combined with low cost storage, enables new ways of working with data pipelines and machine learning workloads.
Users can use Azure Synapse Dedicated Pools for data warehousing workloads, and Databricks for advanced analytics and ad-hoc data exploration.
However, I miss a clear view on what technology I should use to query my data stored in Azure Data Lake Gen 2. How to query parquet or delta files efficiently? How to run simple analytics? There are data virtualization product like Dremio; AWS has Lambda. Is there anything else that I can use in Azure?
In this article I would like to compare Azure Synapse Serverless and Databricks SQL Analytics as query engines on top of Azure Data Lake Gen 2 data.
This article is a vendor neutral attempt to compare Azure Synapse and Databricks when using open data formats. The approach taken uses TPC-DS analytics queries to test performance and available functionalities. However, this is not a thorough performance comparison. Underlying data, Azure Synapse Serverless and Databricks can be further tweaked to optimize query results.
Questions:
For sure there are hundreds of other questions related to SQL compatibility, caching, developer friendliness, cluster vs. endpoint, etc. For now, let’s limit the scope to the questions above.
Use TPC-DS benchmark data to compare Synapse Serverless and Databricks SQL Compute performance and execution cost.
Choices:
Getting data for testing is always a challenge, but luckily there are bright people who created datasets for such benchmarks.
Here are a few links ( link 1, link 2, link 3 ) that helped me to generate required data based on TCP-DS
I have three datasets: 1 GB, 10 GB and 1 TB:
| Table | Avg Row Size in Bytes | 1 GB row counts | 10 GB row counts | 1 TB row counts |
|---|---|---|---|---|
| call_center | 305 | 6 | 24 | 42 |
| catalog_page | 139 | 11,718 | 12,000 | 30,000 |
| catalog_returns | 166 | 143,672 | 1,439,882 | 144,004,725 |
| catalog_sales | 226 | 1,439,935 | 14,400,425 | 1,439,976,202 |
| customer | 132 | 100,000 | 500,000 | 12,000,000 |
| customer_address | 110 | 50,000 | 250,000 | 6,000,000 |
| customer_demographics | 42 | 1,920,800 | 1,920,800 | 1,920,800 |
| date_dim | 141 | 73,049 | 73,049 | 73,049 |
| household_demographics | 21 | 7,200 | 7,200 | 7,200 |
| income_band | 16 | 20 | 20 | 20 |
| inventory | 16 | 11,745,000 | 133,110,000 | 783,000,000 |
| item | 281 | 18,000 | 102,000 | 300,000 |
| promotions | 124 | 300 | 500 | 1,500 |
| reason | 38 | 35 | 45 | 65 |
| ship_mode | 56 | 20 | 20 | 20 |
| store | 263 | 12 | 102 | 1,002 |
| store_returns | 134 | 288,279 | 2,877,632 | 288,009,578 |
| store_sales | 164 | 2,879,789 | 28,800,501 | 2,879,966,589 |
| time_dim | 59 | 86,400 | 86,400 | 86,400 |
| warehouse | 117 | 5 | 10 | 20 |
| web_page | 96 | 60 | 200 | 3,000 |
| web_returns | 162 | 71,772 | 720,274 | 72,002,305 |
| web_sales | 226 | 718,931 | 7,200,088 | 719,959,864 |
| web_site | 292 | 30 | 42 | 54 |
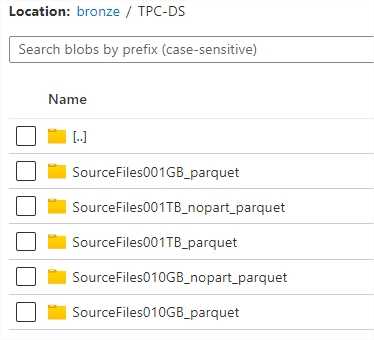
Azure Data Lake Gen 2 bronze zone stores originally generated data (1GB, 10 GB and 1TB datasets) in parquet format.
Silver zone is used to store optimized datasets, converted to delta format. Benchmark tests will run datasets in delta format.
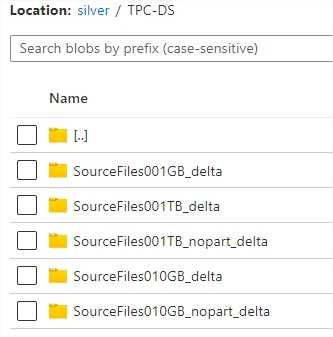
Eventually, there are 5 data versions:
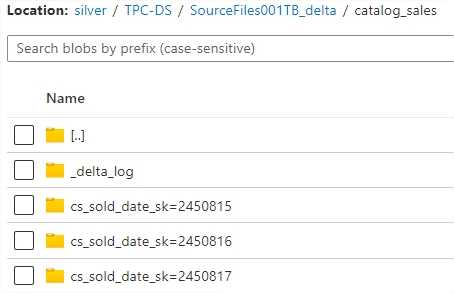
10 GB and 1 TB parititioned database transaction tables are partitioned as following:
Spark-sql-perf library generated data uses ”HIVE_DEFAULT_PARTITION” for NULL value in partition names. Unfortunately, this value is not supported by Synapse partitions. Hence, I manually edit HIVE_DEFAULT_PARTITION to 0 in following tables: Synapse has issues with
All databases are registered in Databricks metastore. Databases separate 1 GB, 10 GB 1TB datasets, delta from parquet table versions, partitioned data from non-partitioned.
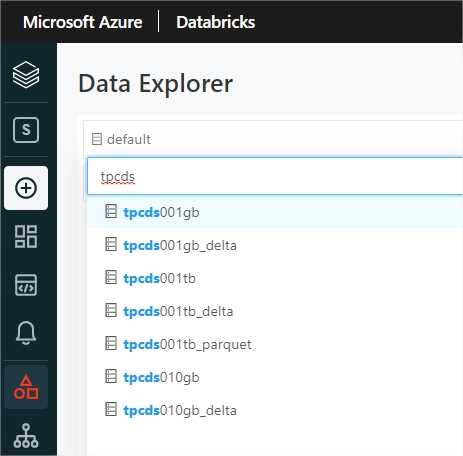
Spark-sql-perf created tables on top of parquet automatically. I’ve moved the files in addition to silver and converted to delta.
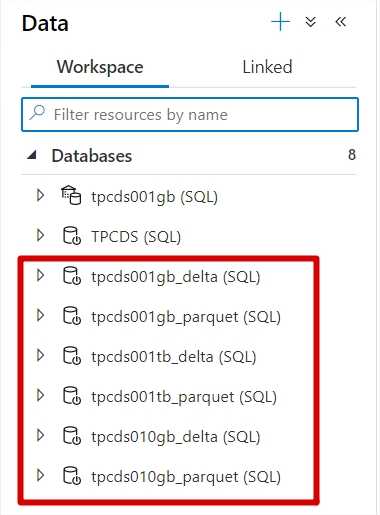
I explicitly define schema and use optimal data types and enforce partition usage with partitioned views.
View definition with partitions (example with DELTA)
CREATE VIEW dbo.inventoryASSELECT *FROM OPENROWSET(BULK 'TPC-DS/SourceFiles010GB_delta/inventory/',DATA_SOURCE = 'vmdatalake_silver',FORMAT = 'DELTA')WITH (inv_date_sk integer,inv_item_sk integer,inv_warehouse_sk integer,inv_quantity_on_hand integer) as a
Also, I decided to check parquet performance with OPENROWSET and EXTERNAL tables.
View definition without partitions (example with PARQUET)
CREATE VIEW dbo.inventoryASSELECT *, CAST(a.filepath(1) AS integer) AS [inv_date_sk]FROM OPENROWSET(BULK 'TPC-DS/SourceFiles010GB_parquet/inventory/inv_date_sk=*/',DATA_SOURCE = 'vmdatalake_bronze',FORMAT = 'PARQUET')WITH (inv_item_sk integer,inv_warehouse_sk integer,inv_quantity_on_hand integer) as a
Parquet as external table
CREATE EXTERNAL TABLE [dbo].[inventory](inv_date_sk integer,inv_item_sk integer,inv_warehouse_sk integer,inv_quantity_on_hand integer)WITH(LOCATION = 'TPC-DS/SourceFiles010GB_parquet/inventory/inv_date_sk=*/',DATA_SOURCE = vmdatalake_bronze,FILE_FORMAT = parquet_format)
There are 90 analytical queries + 24 “warmup” queries (not included in duration calculations). 9 queries were removed as some were failing with Spark SQL (Syntax error or access violation / Query: AEValueSubQuery is not supported) and a few for Synapse. Hence, I left only succeeding queries for both platforms.
JMeter is used often in such testing scenarios. I followed the steps here to set it up on my machine.
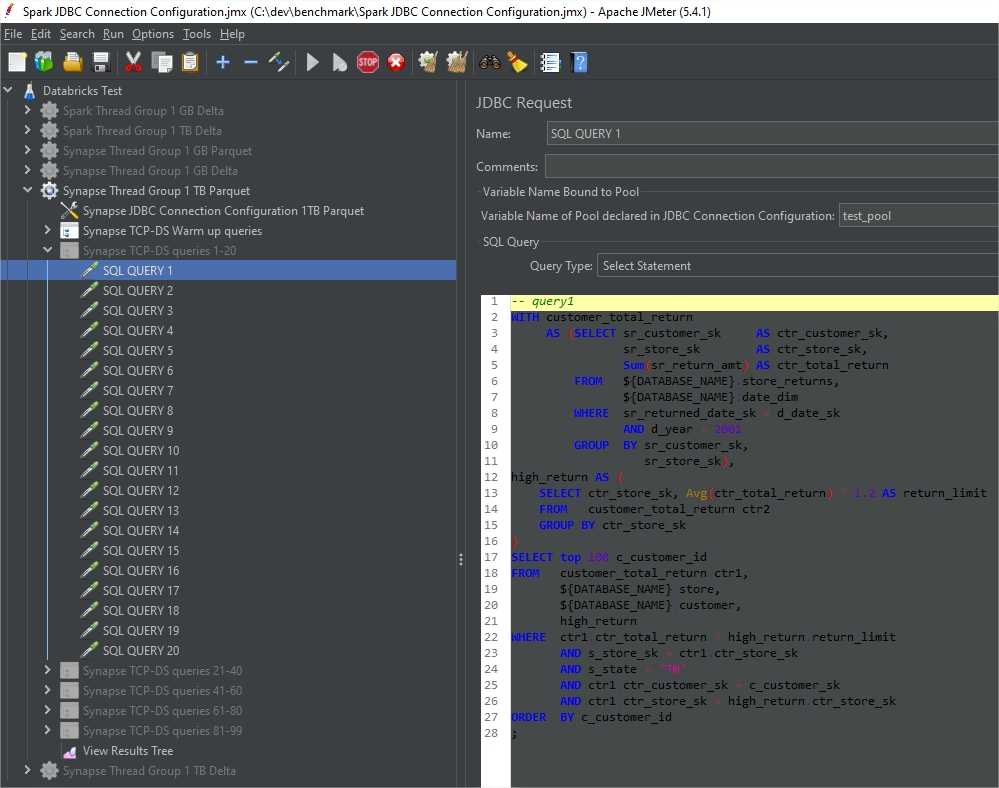
To connect to Databricks SQL, I used Databricks JDBC driver.
And for Synapse Serverless, I used Microsoft JDBC Driver for SQL Server
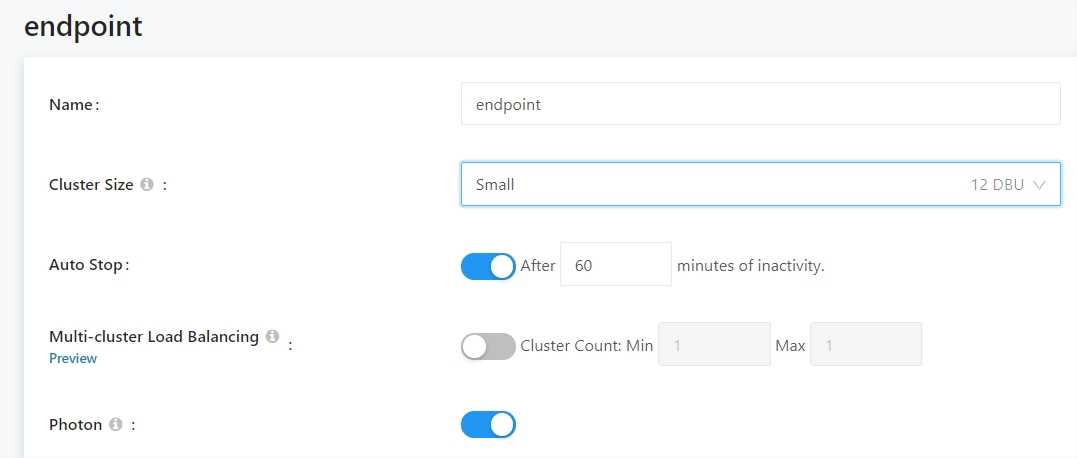
I don’t test concurrent queries, so I disable Multi-cluster Load Balancing
Azure Databricks bills you for virtual machines (VMs) provisioned in clusters and Databricks Units (DBUs) based on the VM instance selected.
Azure Databricks does not charge you until the cluster/endpoint is in a “Ready” state

Total hourly price for SQL Endpoints:
2X-Small - 4 x $0.22/DBU-hour + 2 x $0.58/VM-hour (Standard_E8ds_v4)
X-Small - 6 x $0.22/DBU-hour + 3 x $0.58/VM-hour (Standard_E8ds_v4)
Small - 12 x $0.22/DBU-hour + 4 x $0.58/VM-hour (Standard_E8ds_v4) + 1 x $1.15/VM-hour (Standard_E16ds_v4)
Medium - 24 x $0.22/DBU-hour + 8 x $0.58/VM-hour (Standard_E8ds_v4) + 1 x $2.3/VM-hour (Standard_E32ds_v4)
Large - 40 x $0.22/DBU-hour + 16 x $0.58/VM-hour (Standard_E8ds_v4) + 1 x $2.3/VM-hour (Standard_E32ds_v4)
Disks, Blob storage, IP addresses are billed separately.
You only pay for executed queries and the pricing is based on the amount of data processed by each query. Metadata-only queries (DDL statements) do not incur a cost. Queries will incur a minimum charge of 10 MB and each query will be rounded up to the nearest 1 MB of data processed.
Price: $5 per TB of data processed
All the executed queries are visible in the monitoring tab. To be able to separate tests, I’ve used different SQL users (Submitter) to know which run processed data. It was not possible to filter by the serverless pool name.
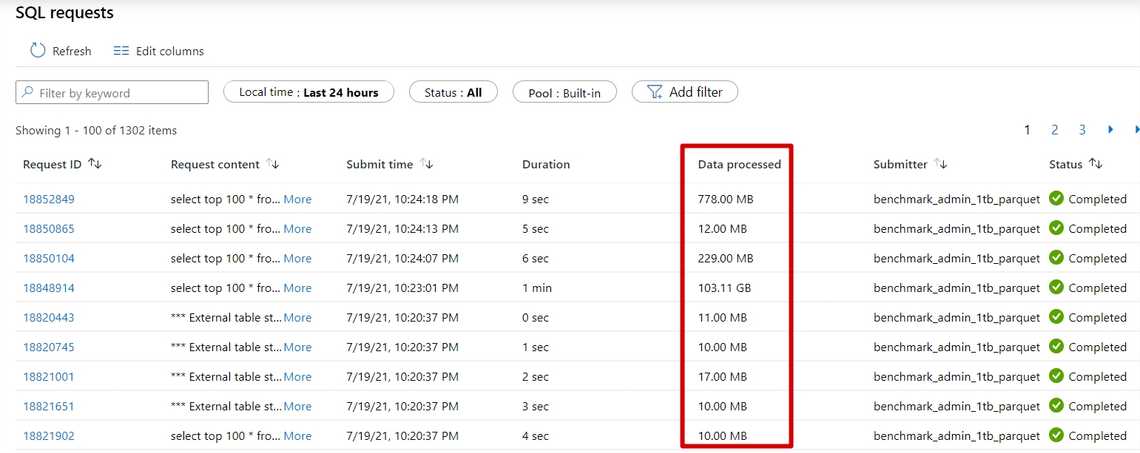
Warmup queries are not included in consumption calculation nor in query execution time
JMeter produces log files in CSV format. I use dbt (Data Build Tool), SQL Analytics as compute and PowerBI as visualization tool.

Dbt project is responsible for all log unification, aggregation logic, etc.
Hosted dbt docs contain more information about lineage, columns, etc.
Finally, I use PowerBI to create simple visualizations (fetches data from SQL Analytics).
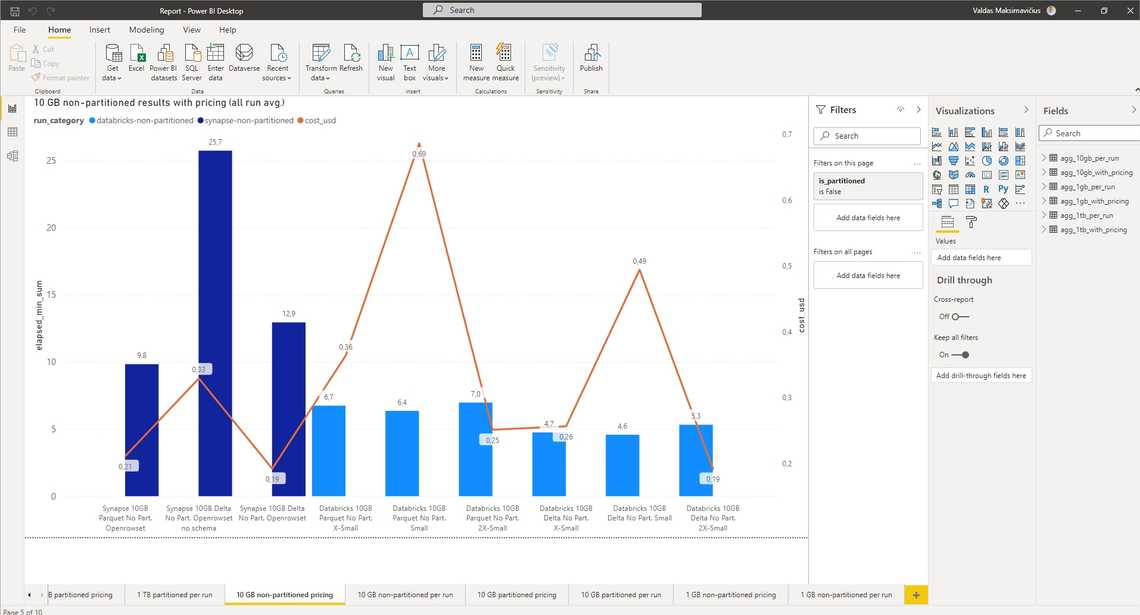
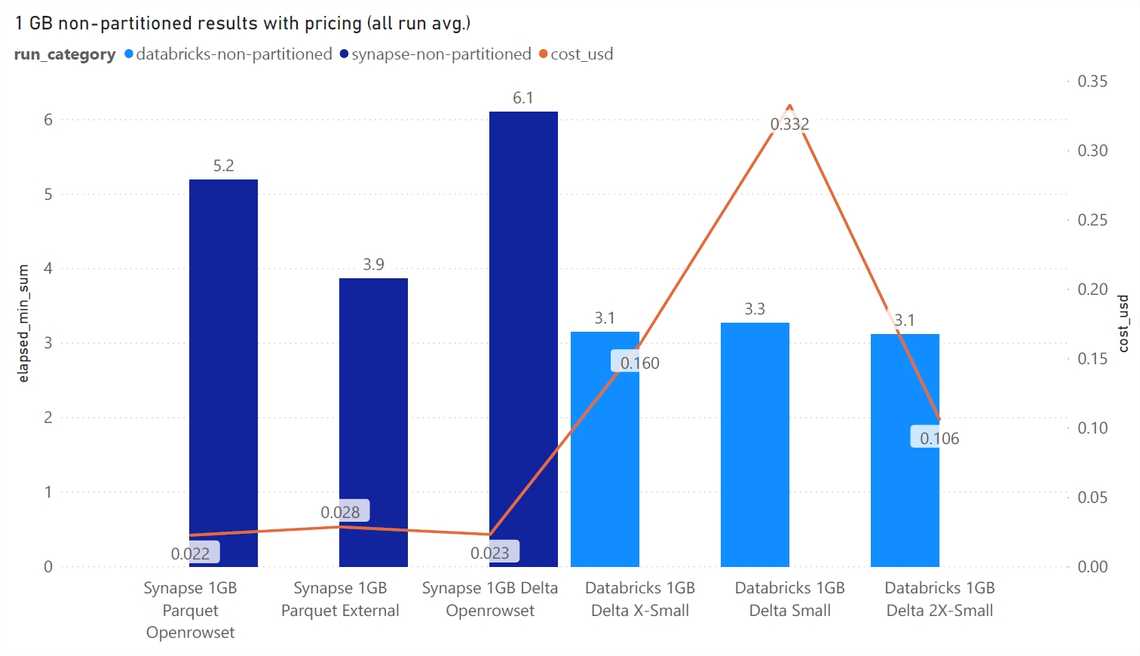
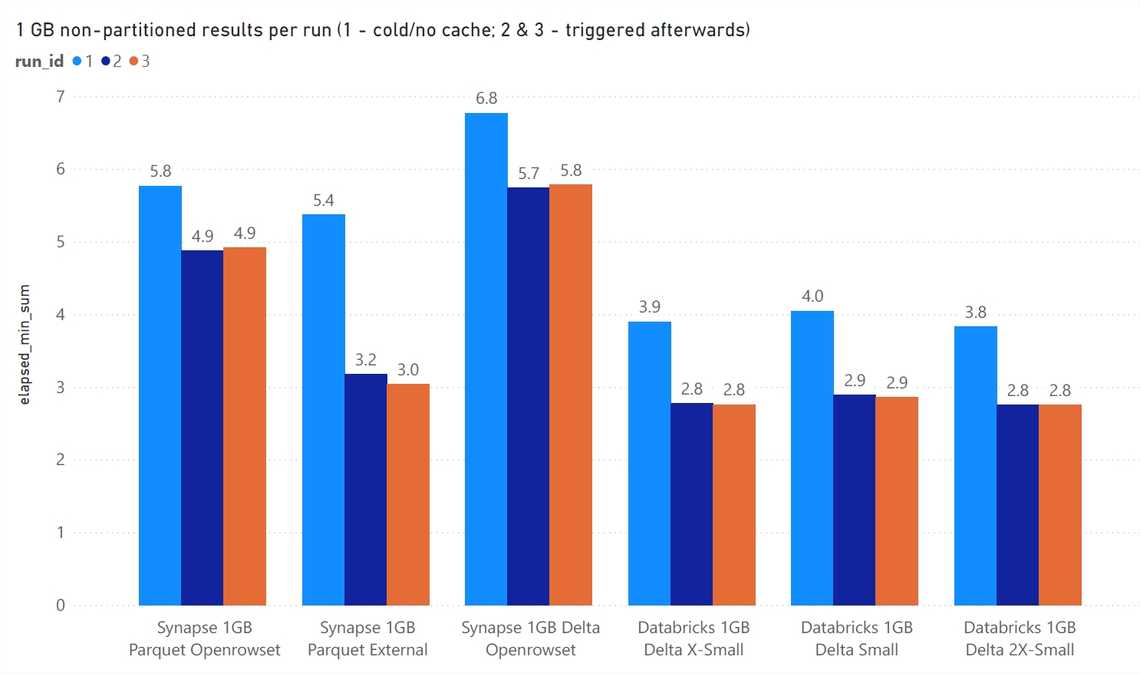
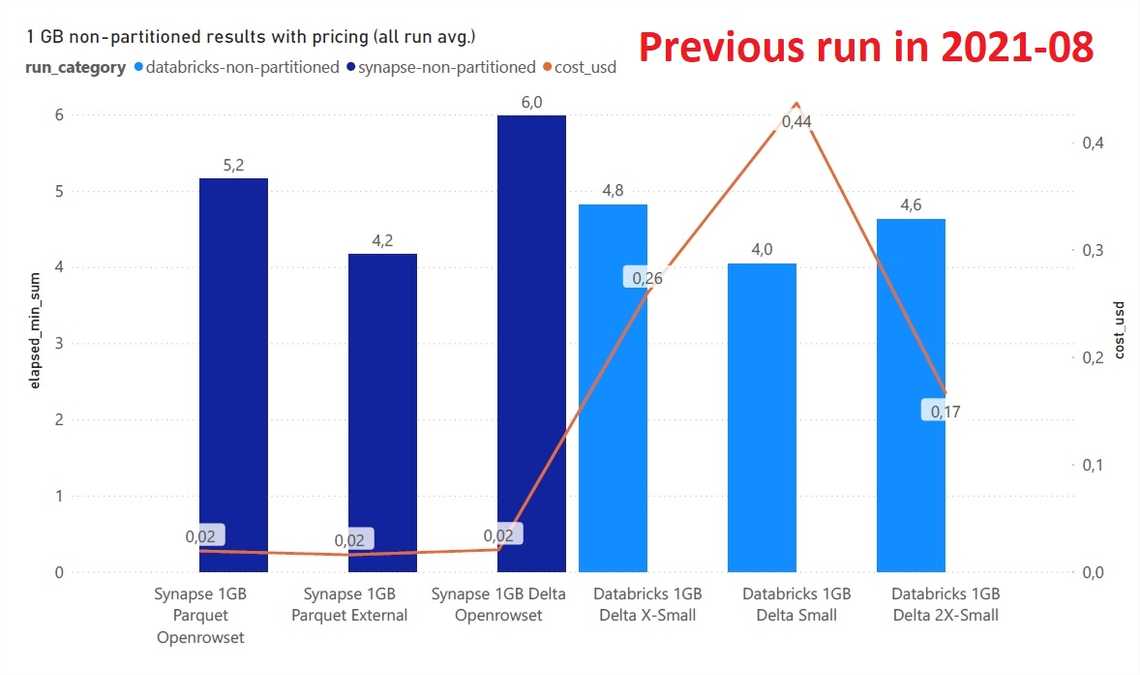
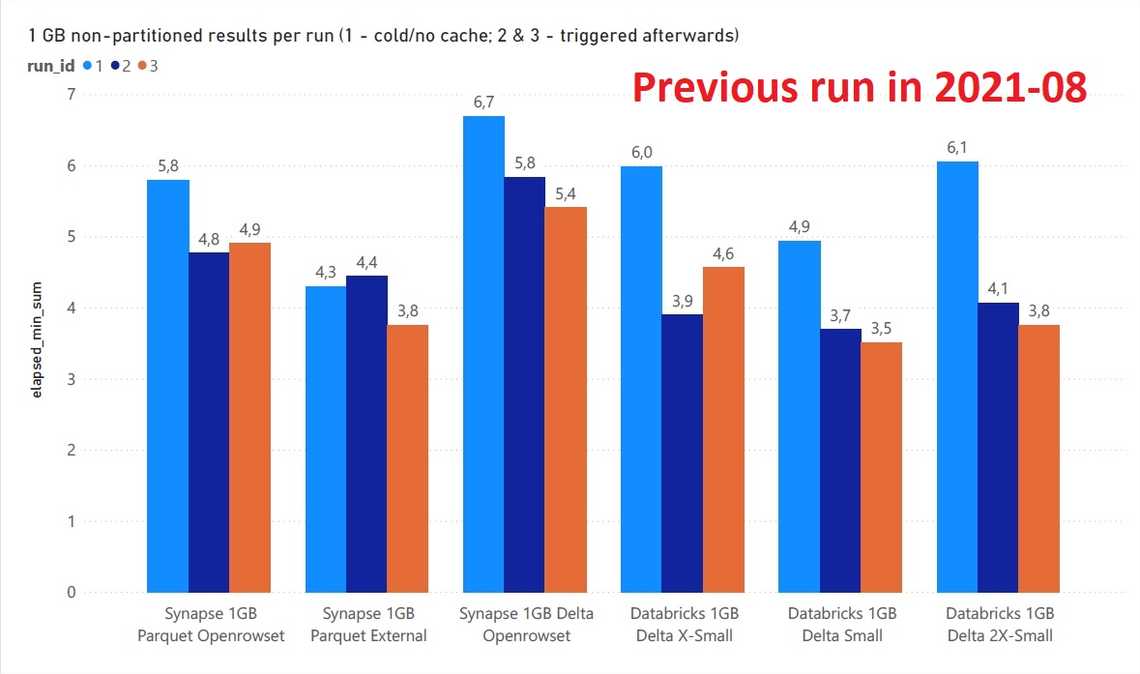
Winner - Azure Synapse Serverless with external tables on parquet files. It provides consistet performance without the need to create/start clusters. Also, Synapse Serverless comes with access management and access APIs similar to SQL Server world.
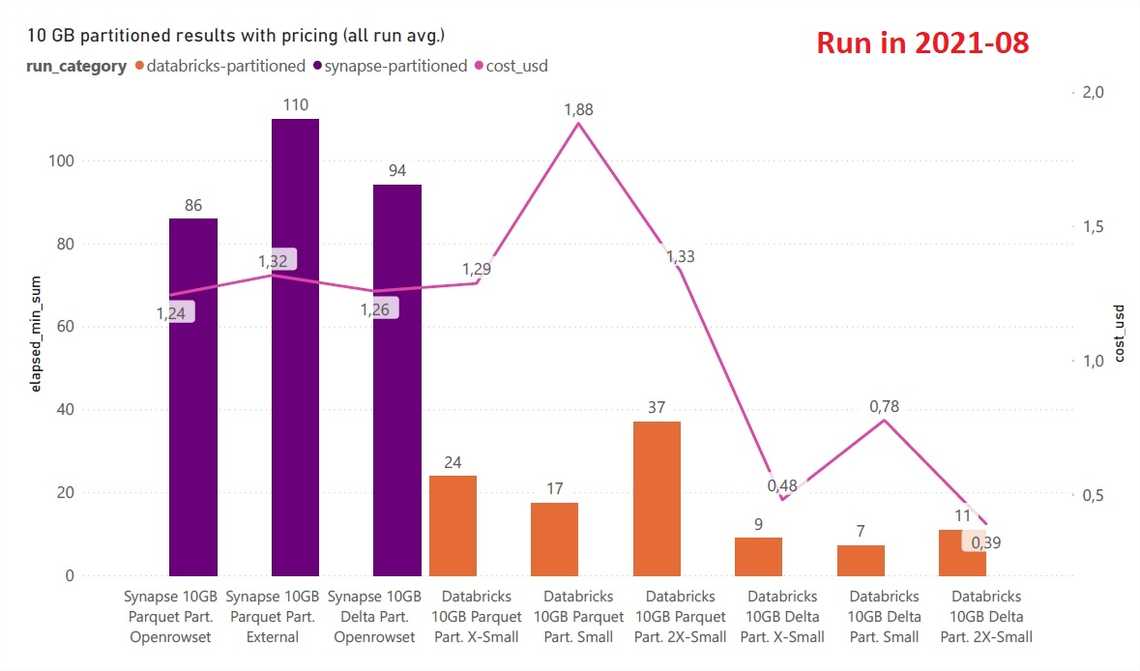
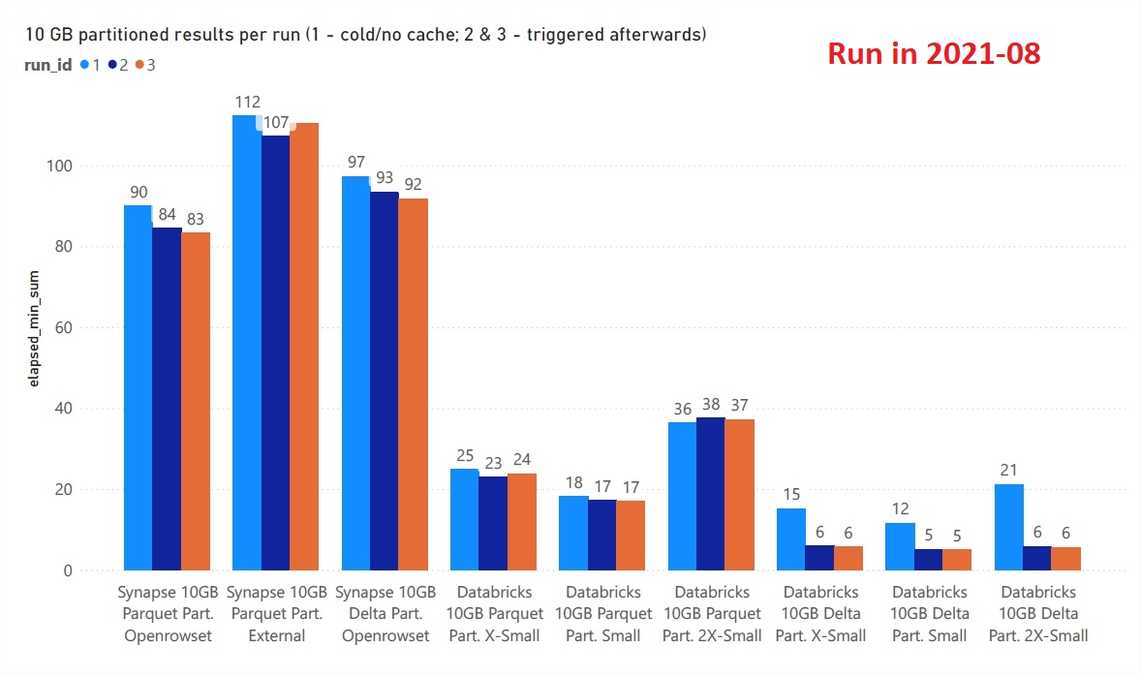
Winner - Databricks SQL Analytics is a faster and cheaper alternative, and better with DELTA.
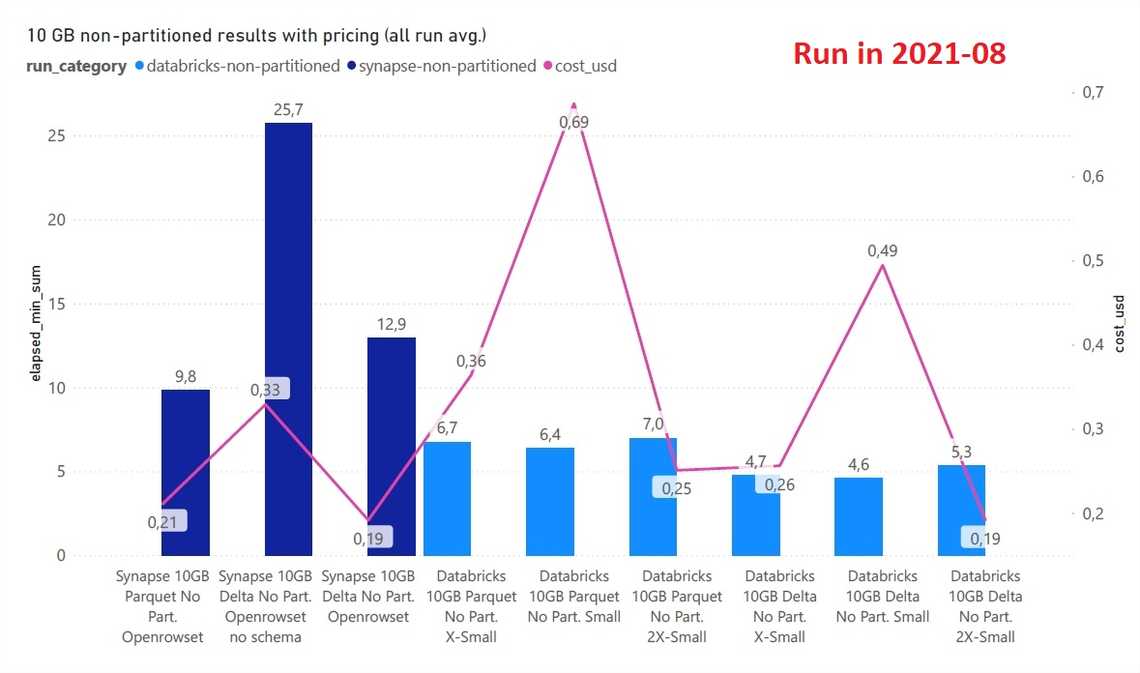
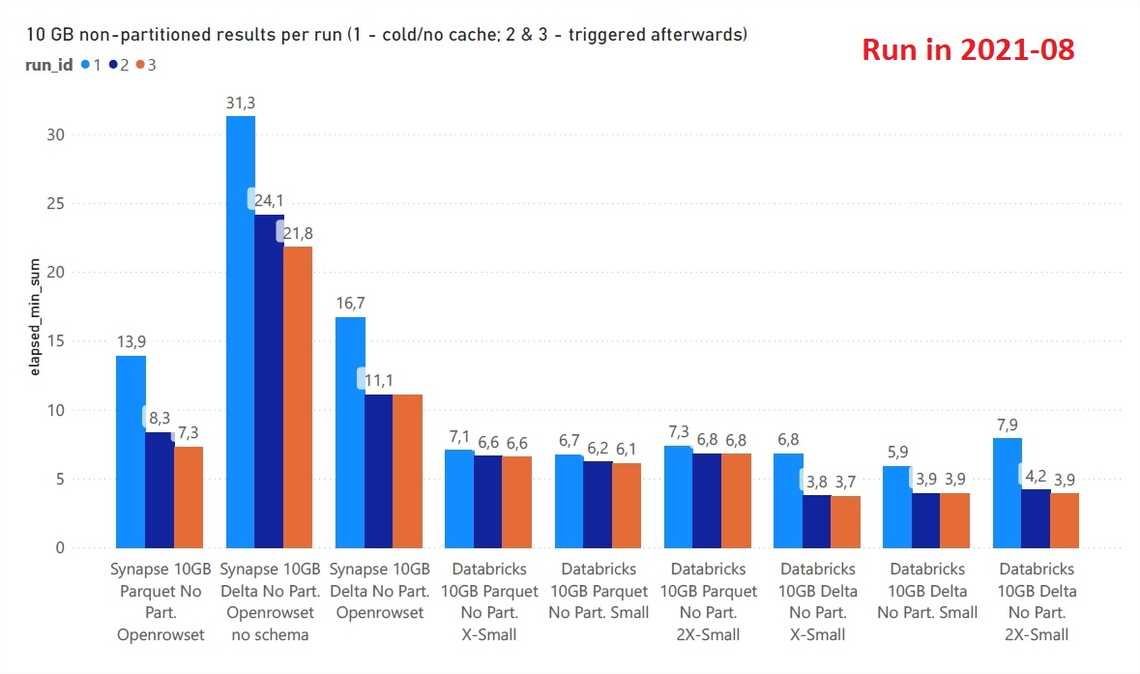
Winner - The execution time considerably shorter compared to partitioned data, but still Databricks SQL Analytics is a faster for the same cost.
Synapse Serverless fails with big number of partitions and files for this data (both for PARQUET and DELTA). Various types of timeouts, exceptions, “There is insufficient system memory in resource pool ‘VDWFrontendPool’ to run this query” where popping up.
A few attempts to run Databricks on PARQUET with large cluster were canceled after hours of slow execution.
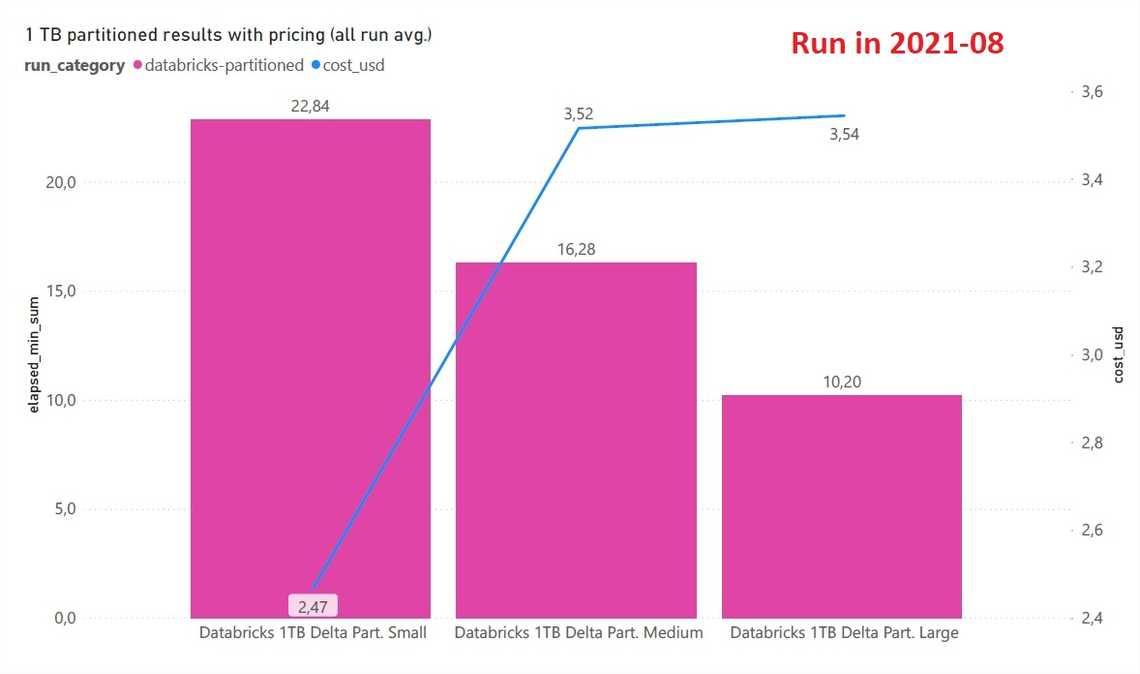
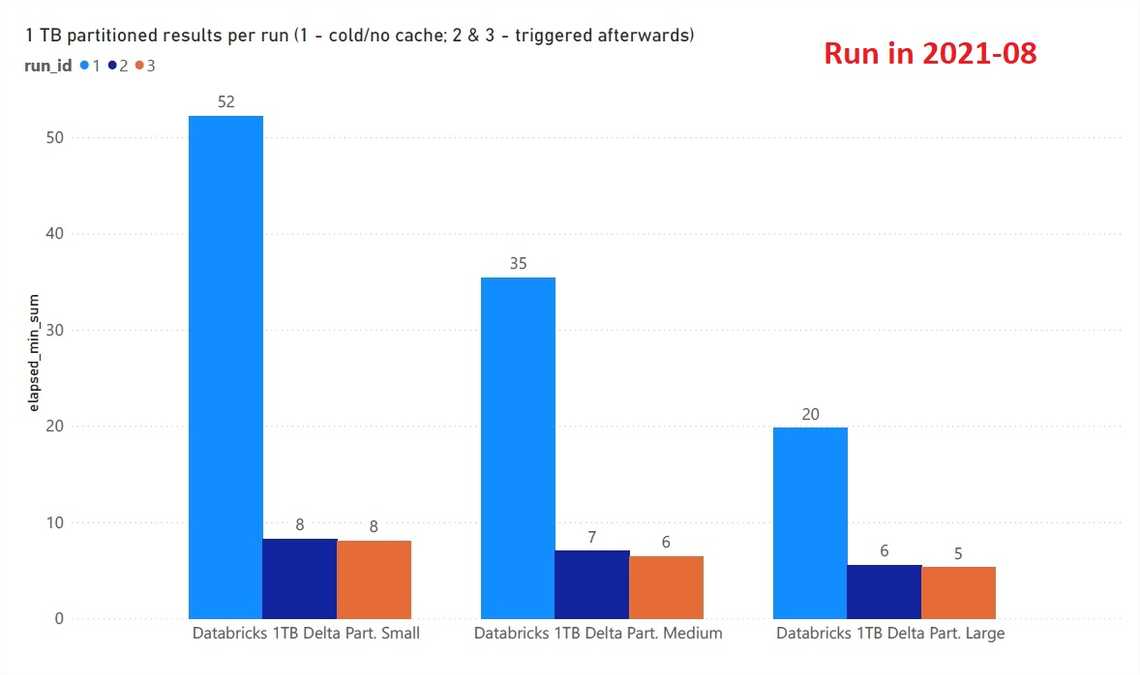
Winner - Databricks SQL Analytics on top of DELTA.
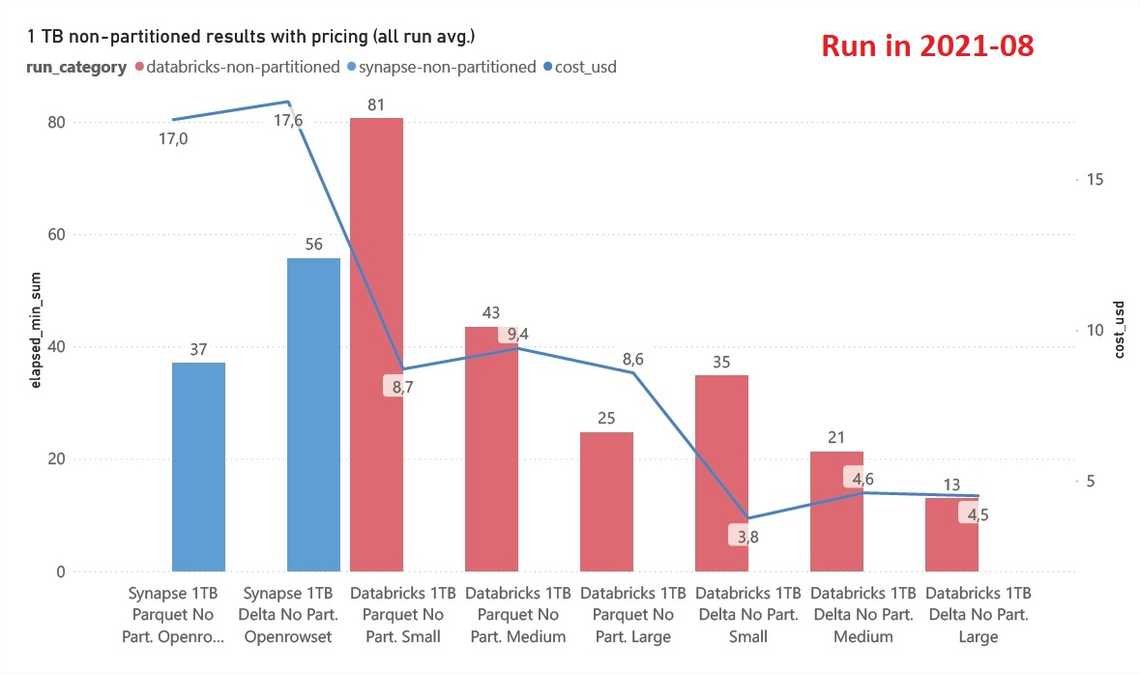
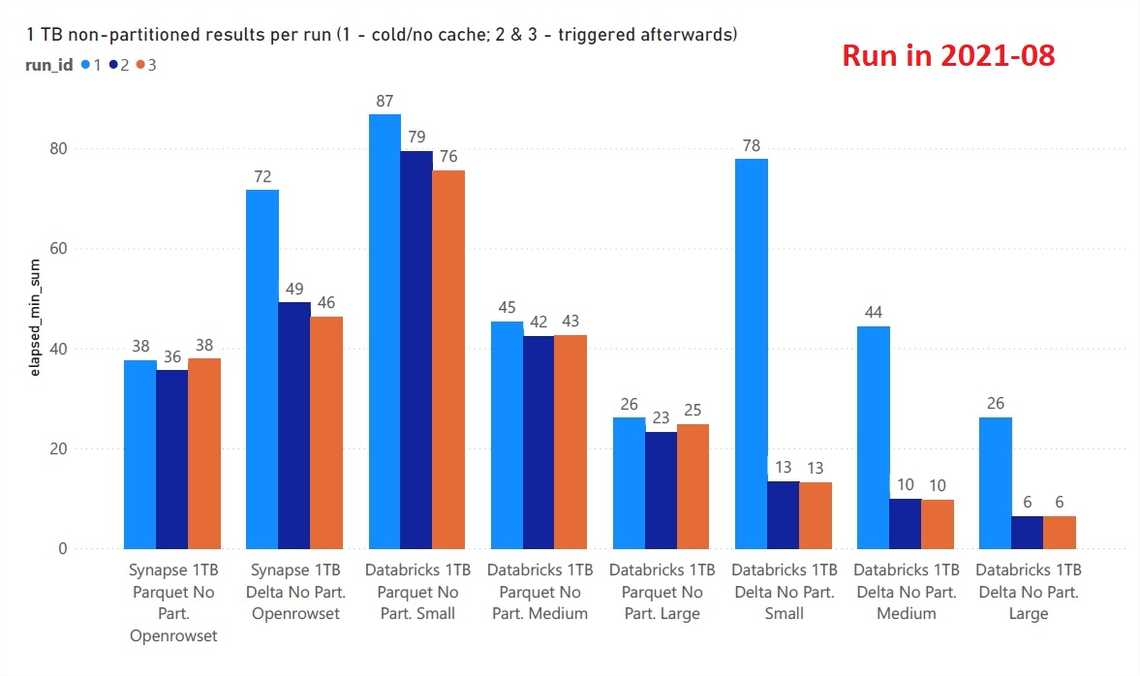
Winner - For PARQUET Synapse Serverless provides similar query times to Databricks, but at a slightly higher cost.
For best overall performance, choose DELTA and Databricks SQL Analytics.
Good
Bad
Good
Bad
Other projects