



Data Engineering Patterns and Principles
March 21, 2021
1 min
Inspired by the growing popularity of Data Build Tool (DBT), I decided to set it up on my PC and explore the tool against Azure storages. You can read more about DBT here.
The series of articles about DBT is a part of my Azure Data Platform Landscape overview project.
dbt does the
TinELT(Extract, Load, Transform) processes – it doesn’t extract or load data, but it’s extremely good at transforming data that’s already loaded into your warehouse.
DBT also has DBT Cloud version with a nice UI. However, why not to try the VSCode and DBT CLI command line experience? :)
There are a few option to get DBT installed on Windows:
The installation steps are based on DBT installation instructions with PIP using local installation for the DBT version 0.18.1.
This blog post is a documentation of steps taken, with all the errors, to help you solve issues if you face similar problems
Be aware that DBT version 0.18 has issues with Python 3.9
C:\dev\dbt>python -m venv dbt-envC:\dev\dbt>.\dbt-env\Scripts\activate.bat(dbt-env) C:\dev\dbt>
(dbt-env) C:\dev\dbt>_pip install dbt
After a while I receive an ERROR: pyopenssl 20.0.1 has requirement cryptography>=3.2, but you’ll have cryptography 2.9.2 which is incompatible.
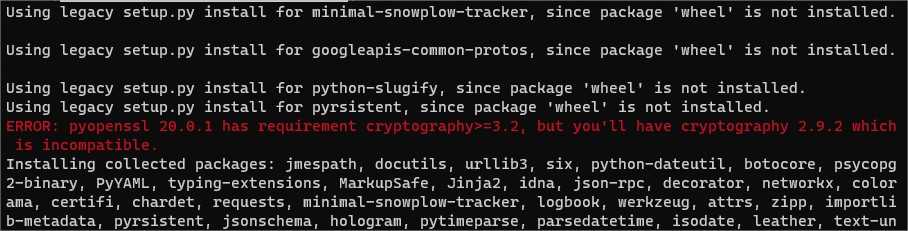
Though installation seems to complete successfully. I try running pip install cryptography, all packages seem to be fine.
Let’s keep this in mind if SSL connections starts fail at the later stages.

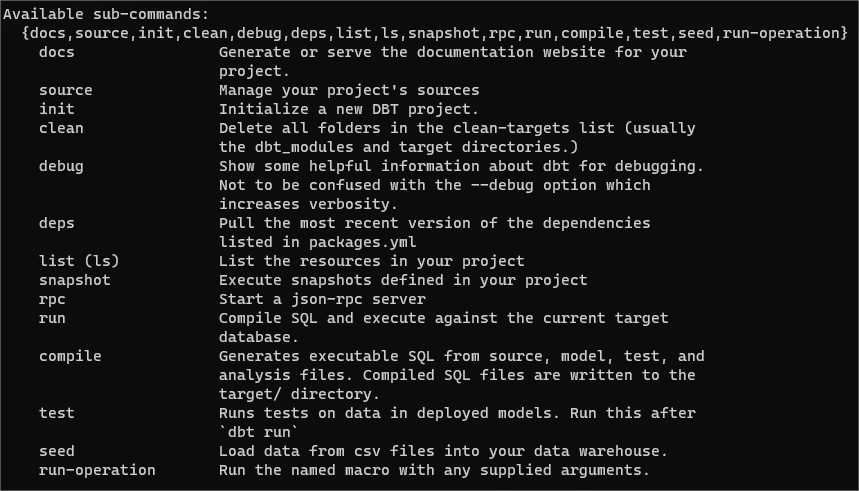
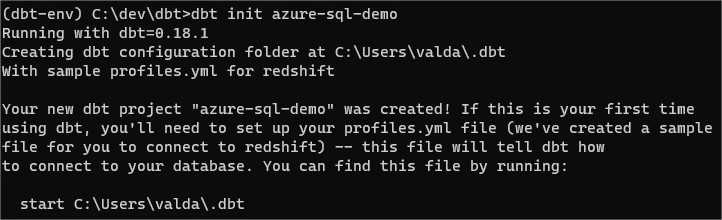
And here is my example project ready in VSCode
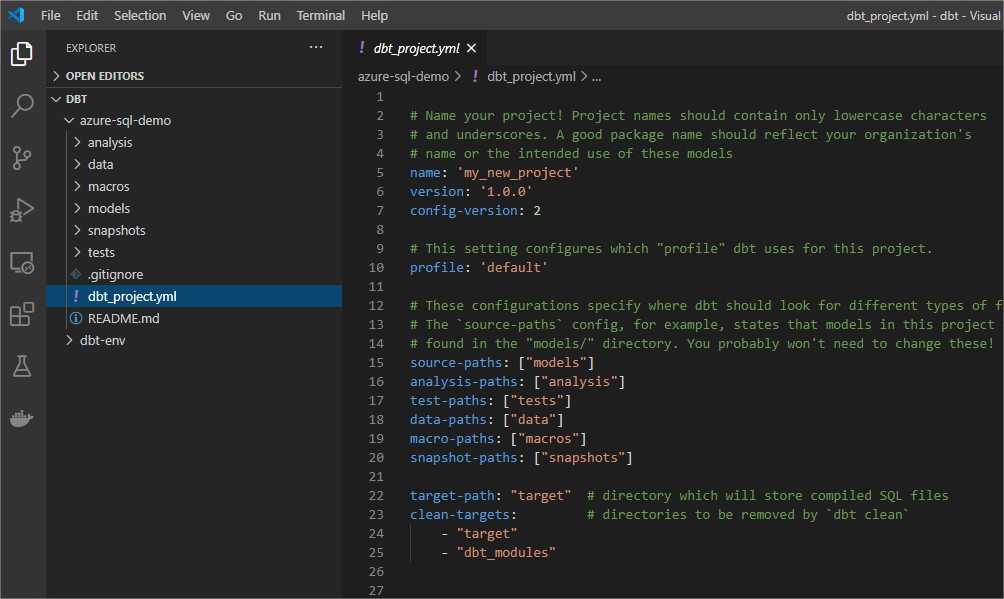
In my demo, I want to connect to Azure SQL. The adapter for SQL is not an official version, so I need to install it manually. You can use other, native targets, e.g. Snowflake, Redshift, or BigQuery.
pip install dbt-sqlserver
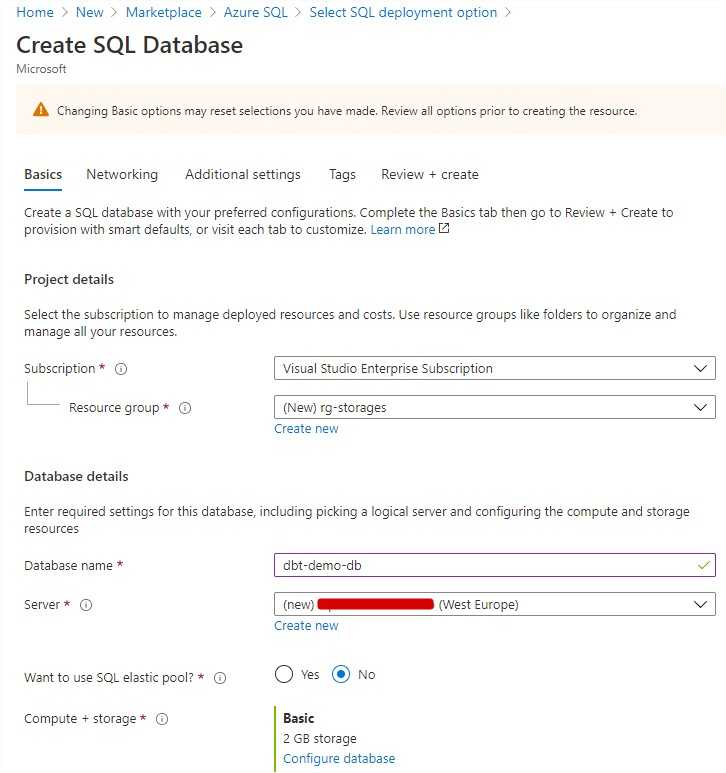
start C:\Users\<<your directory>>\.dbt
The default profiles.yml file contains only generic properties for Redshift. The configuration file contains placeholders for development and production environment. You can have more outputs if needed.
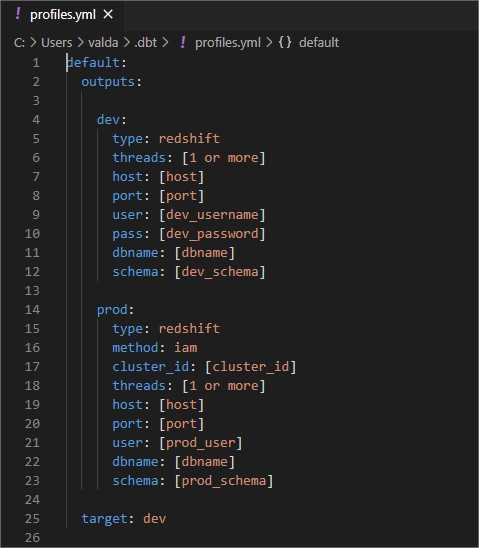
For my demo, I want to add our target database specific connection and modify dbt_project.yml file.
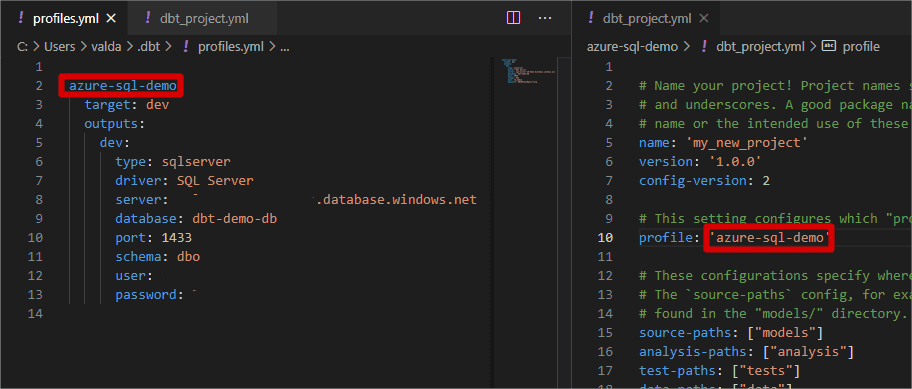
Tiny thing to remember about the driver (left window, line 7) - make sure it has corresponding entry in the ODBC Data Source Administration view. If you miss the driver, install the latest version from the Microsoft repository. I use SQL Server, but there might be other names, depending on package version.
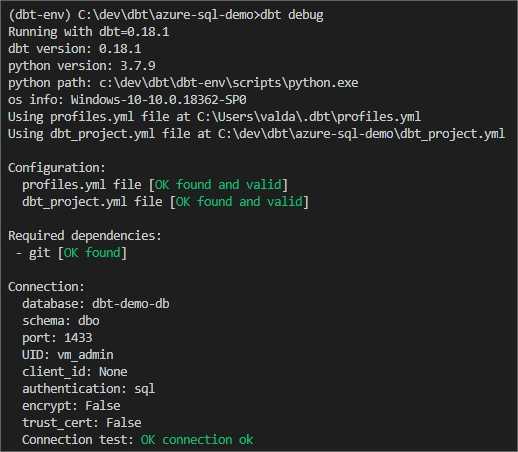
dbt debug
DBT has two example models located in models/example directory.
My_first_dbt_model will be materialized as a table, and my_second_dbt_model should be deployed as a view.
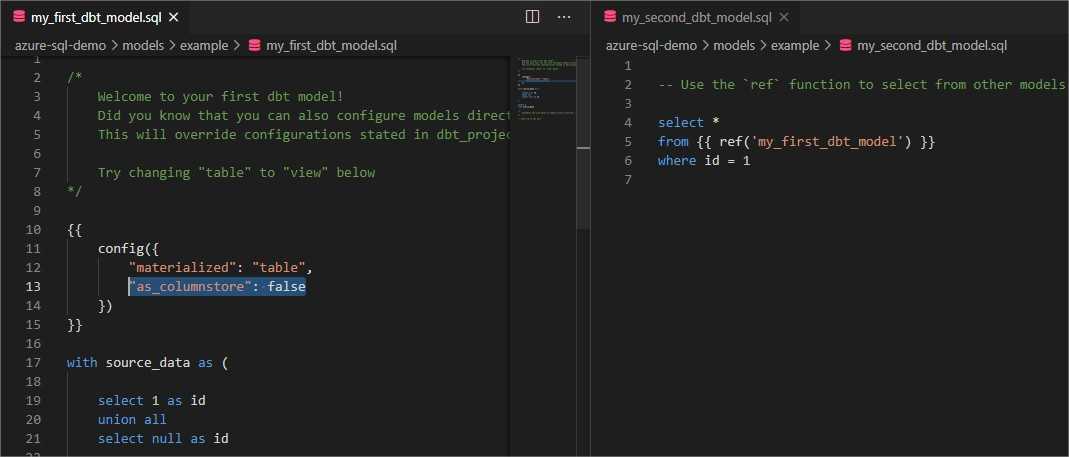
As I am using basic Azure SQL edition, which does not support columnstore indexes, I need to add “as_columnstore: false” setting (left window, line 13)
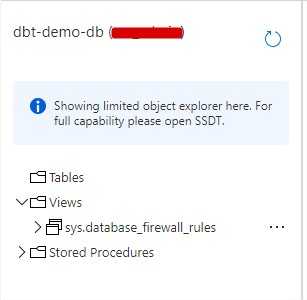
Before any deployment done, here’s a view of my Azure SQL objects (table is empty)
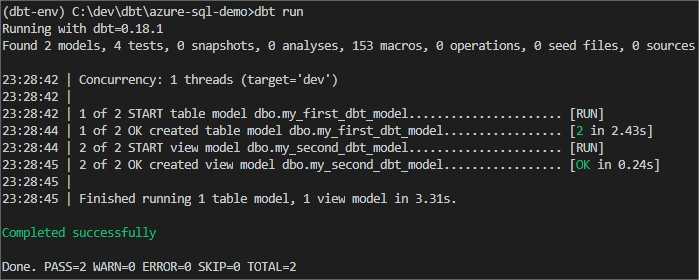
To deploy our models and populate with data, execute command:
dbt run
It should create schema change scripts for all models, and also move data.
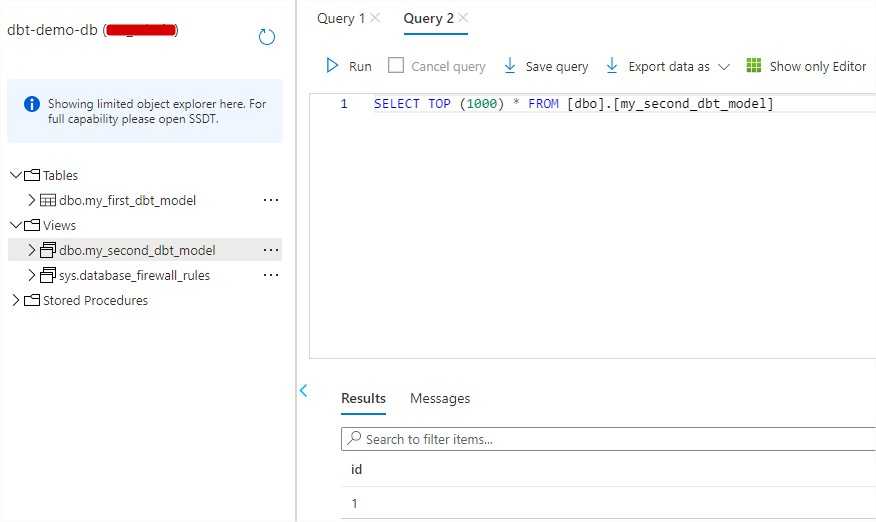
Our Azure SQL database finally contains the objects with some dummy data
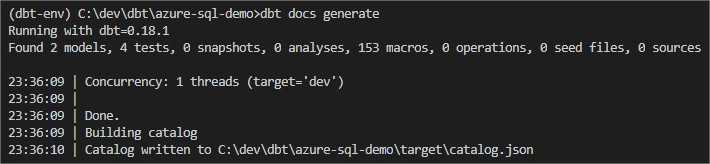
At the end, I would like to verify either document generation and serving works well. First, execute:
dbt docs generate
The function collects all metadata about models and dependecies, and saves it in a json document called - catalog.json
What I would like to do then, is to explore my documentation in a browser window.
dbt docs serve
It spins up local server and opens a browser.
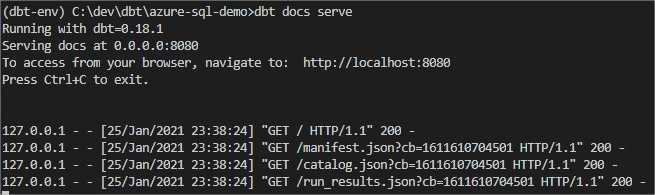
And here is all our documentation, schemas and lineage (running on localhost).
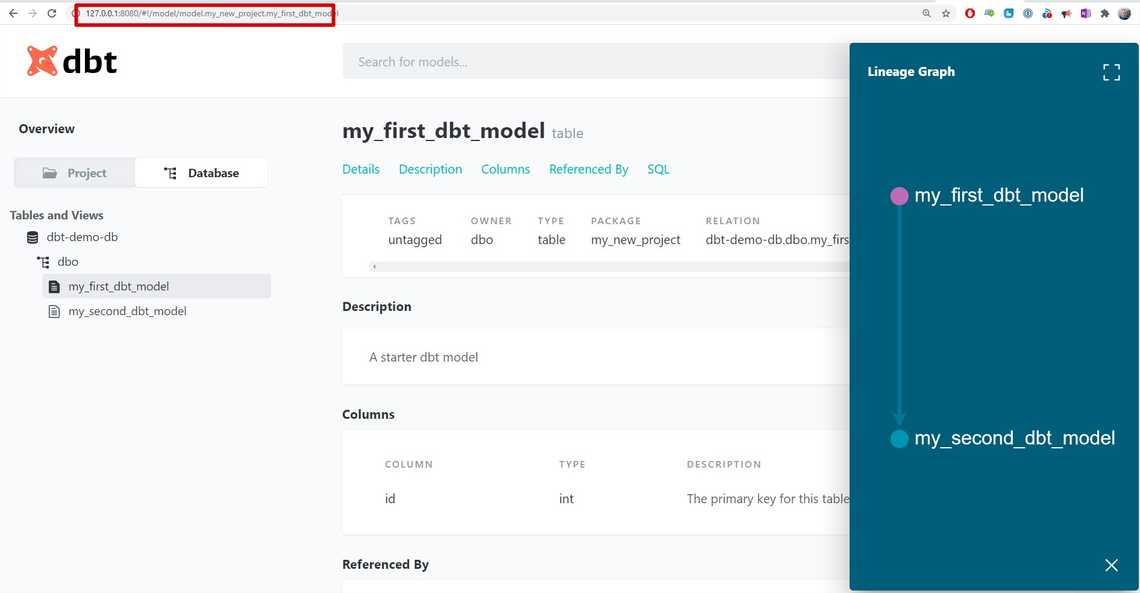
In part 1 we kicked things off with DBT on Windows. You have instructions how to install DBT and connect to Azure SQL. Read part 2 where I explore how DBT works with Azure Synapse.
Other projects