What You Need to Know About Data Governance in Azure Databricks


This article gives you more inputs on how to get started with Databricks and shows the direction for further improvements.
You’ll get to know how to tackle the typical data governance challenges:
- Databricks access controls (users, groups, tokens, etc.)
- Data access controls (credential passthrough, ACLs, service principals, etc.)
- Audit & logging
- Data management (discoverability, quality, lineage)
- GDPR compliance
- Cost Management
- Infrastructure security
Databricks access controls
Users, tokens & user groups
There are a few ways to manage Databricks access:
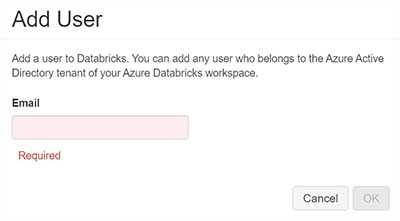
Azure Active Directory users
Access to Databricks is granted by entering employee’s email. All users have to be present in Azure Active Directory. Also, it’s a viable option for system users too.
Databricks groups
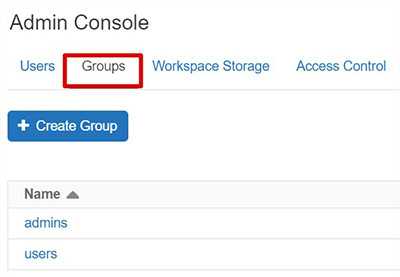
Databricks groups are not connected to Azure Active Directory. Hence it’s required to define groups and assign users. You might consider applying similar name as your Azure Active Directory groups. These groups are crucial while setting up access on clusters, notebooks, etc.
Tokens
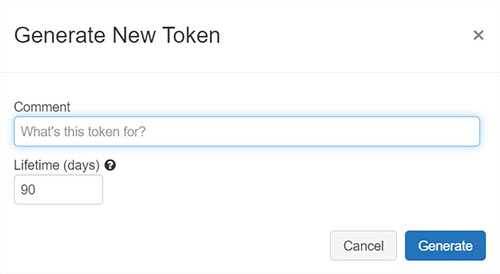
Personal Access Tokens can secure authentication to the Databricks API instead of passwords.
Clusters & workspace objects
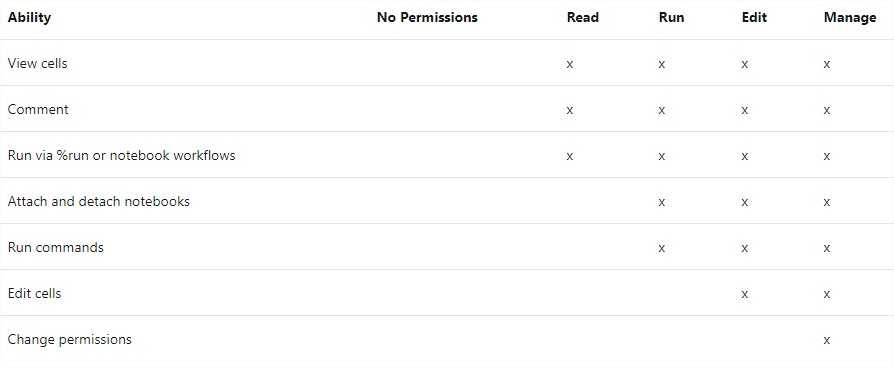
Setting up access on clusters, notebooks, MLFlow experiments is straight forward:
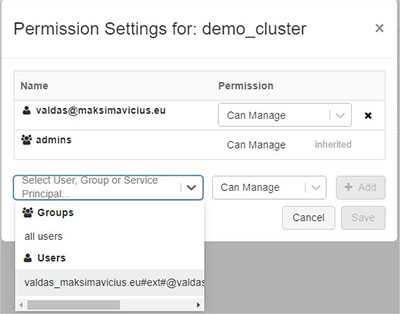
To ensure you give proper permission, take a look at detailed documentation.
Secret scopes a.k.a key vaults
Use secret scopes to hide password and secrets inside notebooks. Good news that you can use these secrets also in cluser configurations.
jdbcUsername = dbutils.secrets.get(scope = "jdbc", key = "username")jdbcPassword = dbutils.secrets.get(scope = "jdbc", key = "password")
There are two types of scopes: Azure Key Vault-backed scopes and Databricks-backed scopes. Azure Key Vault is often a better choice as it gives more control over your secrets. You can read more them here.
Cluster policies
Be careful with who creates and manages clusters. A cluster policy limits the ability to configure clusters based on a set of rules.
- Limit users to create clusters with prescribed settings
- Simplify the user interface and enable more users to create their own clusters (by fixing and hiding some values)
- Control cost by limiting per cluster maximum cost
SCIM Integration
Azure Databricks supports SCIM, or System for Cross-domain Identity Management, an open standard that allows you to automate user provisioning using a REST API and JSON.
Using SCIM you create users, user groups and service principals in Databricks. Give them the proper level of access, temporarily lock and unlock user accounts, and remove access.
Example request to add Service Principal
POST /api/2.0/preview/scim/v2/ServicePrincipals HTTP/1.1Host: <databricks-instance>Authorization: Bearer dapi48…a6138bContent-Type: application/scim+json
{"schemas":["urn:ietf:params:scim:schemas:core:2.0:ServicePrincipal"],"applicationId":"b4647a57-063a-43e3-a6b4-c9a4e9f9f0b7","displayName":"test-service-principal","groups":[{"value":"123456"}],"entitlements":[{"value":"allow-cluster-create"}]}
Data access controls
Implement table access control
By default, all users have access to all data stored in a cluster’s managed tables. To limit that, one can use table access control to set permissions for data objects on a cluster. Also, one can create dedicated Hive views and apply Row Level Security. Read more about Table access control

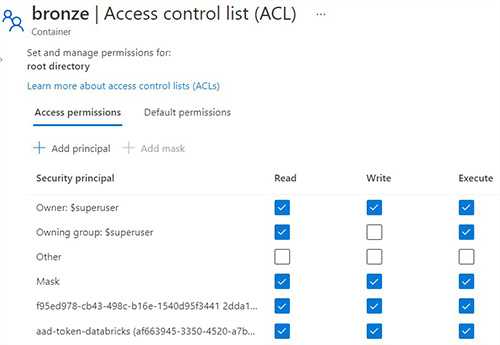
Secure access to Azure Data Lake Storage
First, setup permissions on Azure Data Lake Gen 2 using ACLs. Read more about Data Lake Gen 2 ACLs
Credential passthrough
Use Azure Active Directory credential passthrough to enable access for your users. Ensure the user’s email used to log in to Databricks and set ACLs is the same. Read more about accessing data from ADLS using Azure AD
p.s. PowerBI Databricks connects supports credential passthrough too.

Don’t forget that you can mount a storage and still use credential passthrough - read more.
Be aware that credential passthrough has many limitations: disabled Scala, unsupported Data Factory, no DBFS, and more.
Service principals
As stated above, Data Factory does not work with credential passthrough. For long-running or frequent workloads, automated jobs, you still want to use system users.
spark.conf.set("fs.azure.account.auth.type.<storage-account-name>.dfs.core.windows.net", "OAuth")spark.conf.set("fs.azure.account.oauth.provider.type.<storage-account-name>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")spark.conf.set("fs.azure.account.oauth2.client.id.<storage-account-name>.dfs.core.windows.net", "<application-id>")spark.conf.set("fs.azure.account.oauth2.client.secret.<storage-account-name>.dfs.core.windows.net", dbutils.secrets.get(scope = "<scope-name>", key = "<key-name-for-service-credential>"))spark.conf.set("fs.azure.account.oauth2.client.endpoint.<storage-account-name>.dfs.core.windows.net", "https://login.microsoftonline.com/<directory-id>/oauth2/token")
SQL Databases
Usernames and passwords are required to access sources like Azure SQL, SQL Server, MySQL, PostgreSQL. Key Vault is a good place to store such credentials.
jdbcUrl = "jdbc:mysql://{0}:{1}/{2}".format(jdbcHostname, jdbcPort, jdbcDatabase)connectionProperties = {"user" : jdbcUsername,"password" : jdbcPassword,"driver" : "com.mysql.jdbc.Driver"}
Big Query
Other storages, like BigQuery, might require key-based authentication. Cluster based environment variables would do the trick
GOOGLE_APPLICATION_CREDENTIALS="/home/user/Downloads/service-account-file.json"
And that is enough to access your data within the cluster.
df = spark.read \.format("bigquery") \.load("bigquery-public-data.samples.shakespeare")
Enhanced access control
Default Databricks governance controls might not be sufficient for large enterprises. You might check out COTS tools, like Immuta, Privacera, Okera. Take a look at my exploration of Immuta.
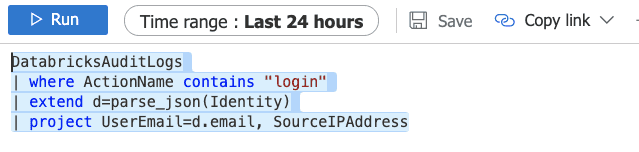
Audit & logging
Always enable diagnostic logging for Databricks and other services. It delivers plenty of valuable information out-of-the-box. And allows custom logging too.
Information groups logged by Databricks:
- dbfs
- clusters
- accounts
- jobs
- notebook
- ssh
- workspace
- secrets
- sqlPermissions
- instancePools
Information groups logged by Azure Data Lake:
- StorageRead
- StorageWrite
- StorageDelete
- Transaction
Data Management
Data discovery
Databricks provides table and database search functionality. But, it isn’t enough for a complete data discovery and documentation.
Azure Purview is an Apache Atlas based Azure data catalog, but it’s still in early phases of development.
If you look for an enterprise ready data catalog, take a look at Alation:
Read more about various data governance tools.
Lineage
Getting automated Spark lineage delivered to your data catalog is tough, but not impossible. Here are lineage example with Spline library - article 1, article 2.
Another option is to push manual lineage, visualized here.
Also, consider using Azure Data Factory for orchestration. With a proper ADF pipeline structure, you can have a high level lineage and help you see dependencies and rerun failed activities. You can read more about Data Factory dependency framework here
Data quality
By default Databricks doesn’t provide any features here. But good news are there are great packages available.
For example, Great Expectations, Deequ.
Also, there might be no need for any fancy data quality libraries. Simple asserts can help you control data better.
GDPR compliance
Below are a few examples about GDPR and CCPA compliance. For a complete Azure Databricks GDPR compliance look here.
Implementing “right to be forgotten”
Delta Lake supports several statements to facilitate deleting data from and updating data in Delta tables - read more.
MERGE INTO usersUSING opted_out_usersON opted_out_users.userId = users.userIdWHEN MATCHED THEN DELETE
Retention
By default, Delta Lake retains table history for 30 days and makes it available for “time travel” and rollbacks. That means that, even after you have deleted personal information from a Delta table, users in your organization may be able to view that historical data
To delete all customers who requested that their information be deleted, and then remove all table history older than 7 days, you simply run:
VACUUM gdpr.customers
Privacy protection patterns
Unfortunately, there are no built-in data anonymization or encryption patters. It’s up to you to implement it based on privacy pattern that suits your scenario best:
Privacy protection at the ingress
- Scramble on arrival
- Simple to implement
- Limits incoming data = limited value extraction
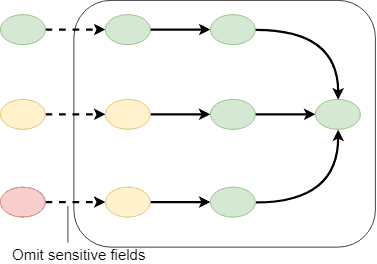
Example - load data from a source through a SQL view that limits sensitive data
CREATE VIEW masked.dwh_customer ASSELECTid,(CASE WHEN email IS NULL THEN 0 ELSE 1 END) AS hasEmail,postalCode,customerTypeFROM dwh.customer
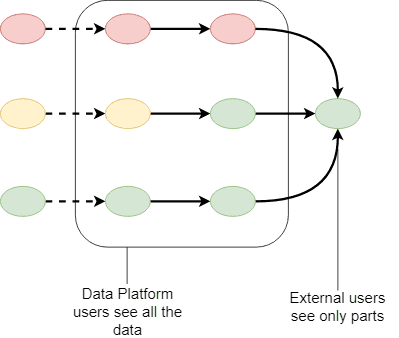
Privacy protection at the egress
- Processing in an opaque box
- Enabling more use cases
- Strict export operations required
- Exploratory analytics need explicit egress/classification
Anonymisation
- Discard all PII (e.g., user id)
- No link between records or datasets
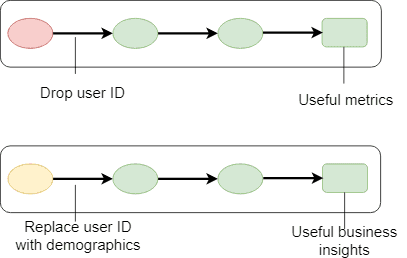
Example - drop sensitive columns with Apache Spark
df = spark.read.parquet("/mnt/data/customer")df = df.drop("nin", "address", "phoneNumber")
Further improvement would be to get a list of sensitive columns for each dataset and skip it automatically.
Pseudonymization
Records and datasets are linked Hash PII
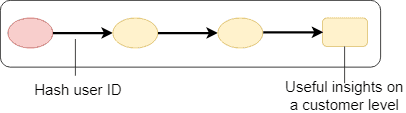
Example - hash sensitive column
UPDATE gdpr.customers_lookup SET c_email_address_pseudonym = sha2(c_email_address,256)
Cost Management
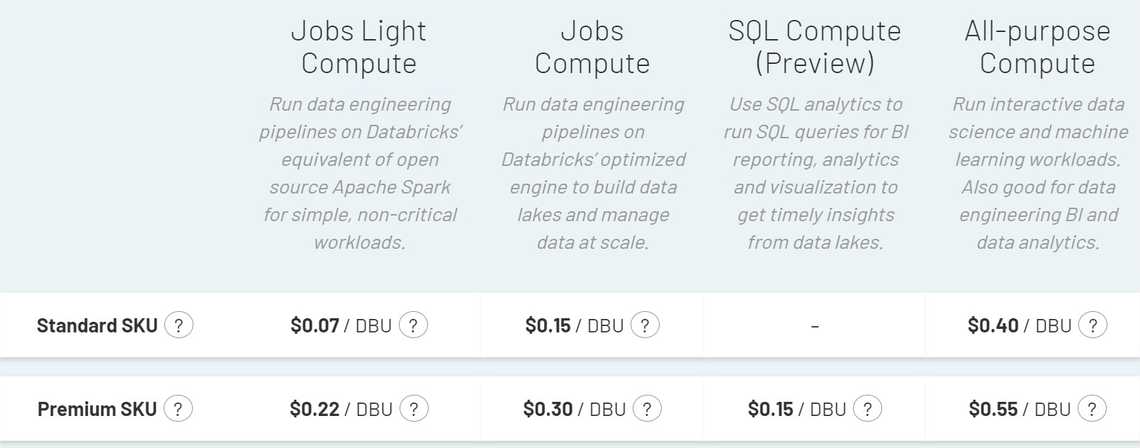
Get familiar with pricing, cluster differences. Probably the biggest mistake you can do is to use all-purpose computes for all your activities.
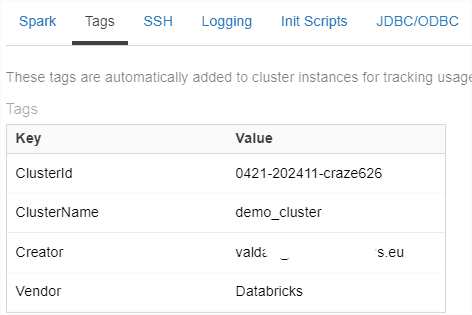
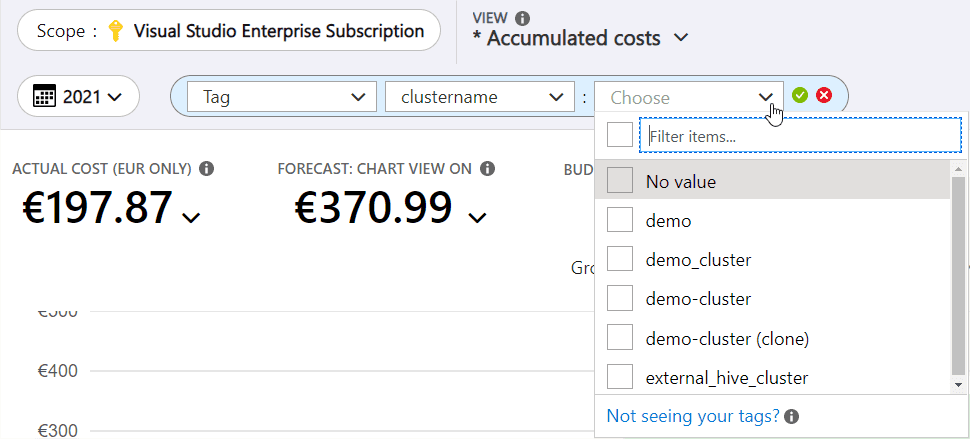
If you use more clusters than 1, put cluster tags to identify your workloads and filter in Azure Cost Management.
Infrastructure security
Make sure to add security elements (e.g. NSG, ExpressRoute). Here is an Azure Databricks - Bring Your Own VNet reference architecture:
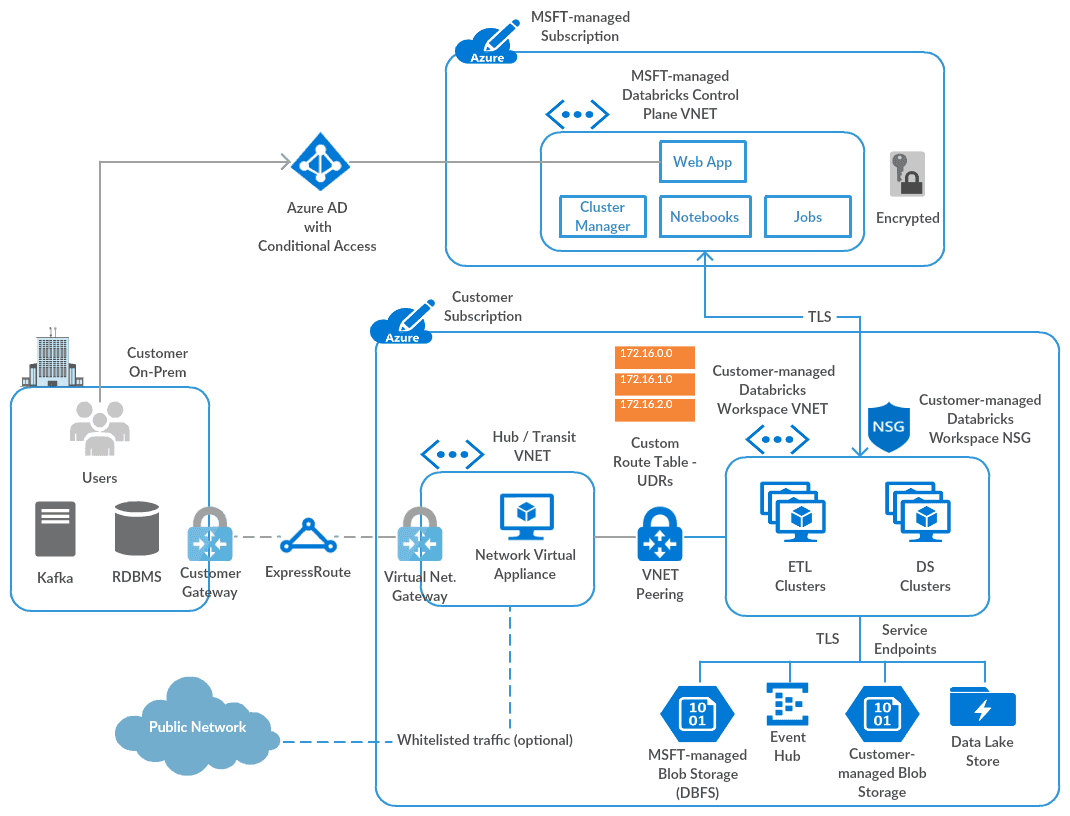
Read more about secure cluster connectivity.
As you can see, setting up Data Governance in Databricks is not straighforward. There are many moving parts that require custom implementation.
Share


Related Posts
Other projects