What is Immuta and how does it improve data governance in Databricks? - Part 2


Welcome! Here are the series of articles about Immuta. In part 1 we kicked things off with Immuta. We connected to a data source and observed data policies in action.
- Part 1 - Getting Familiar and connecting to sources
- Part 2 - Policies, catalog, my feedback - Your are here
Collaboration and data catalog
Immuta’s UI feels modern and friendly. Tips and pop ups help understand the tool even faster. In addition to data policy features, there are metadata management and data dictionary functionalities.
First of all - search. Find all registered tables (restricted tables are not even visible via search).
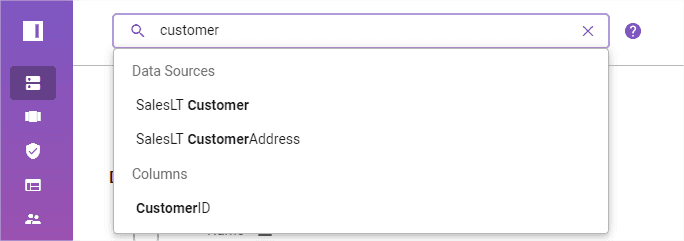
There is a Data Dictionary tab to look up schema, tagging, and description. One can also connect through APIs to external data catalogs.
If something is unclear about tables, column descriptions, user can ask questions and create tasks via Immuta Discussions tab. The table owner will be notified.

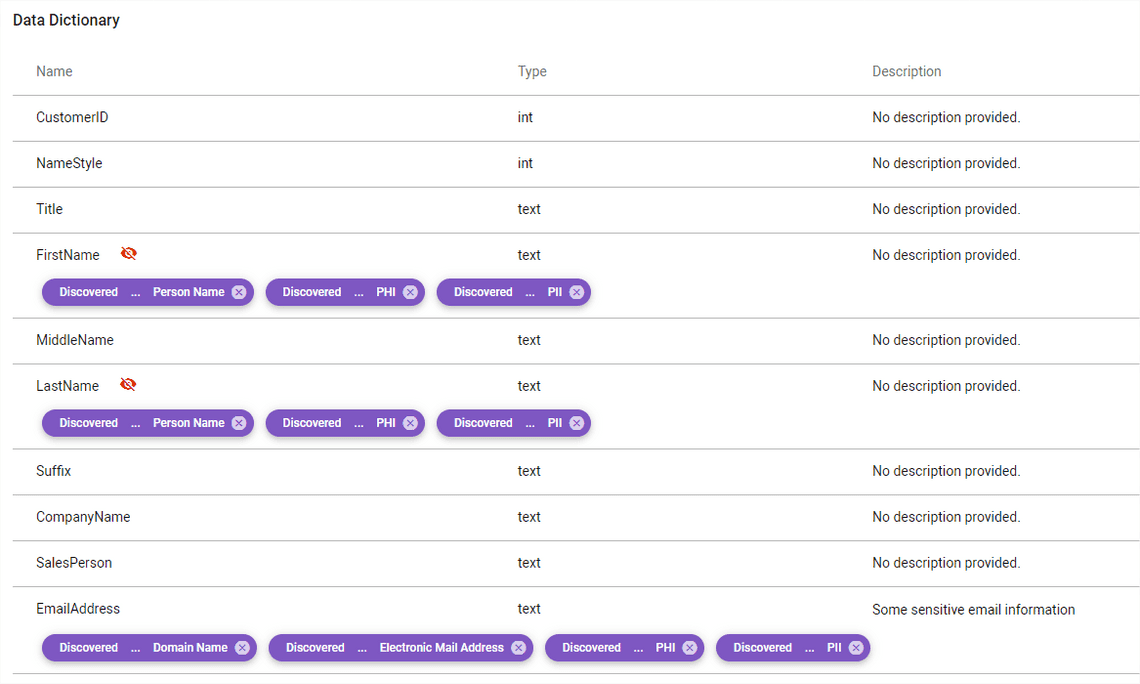
There is also Lineage tab, but that’s where I am surprised to see just project names using the table. Maybe it can show something more, but that’s not and end-to-end lineage of all data pipelines.
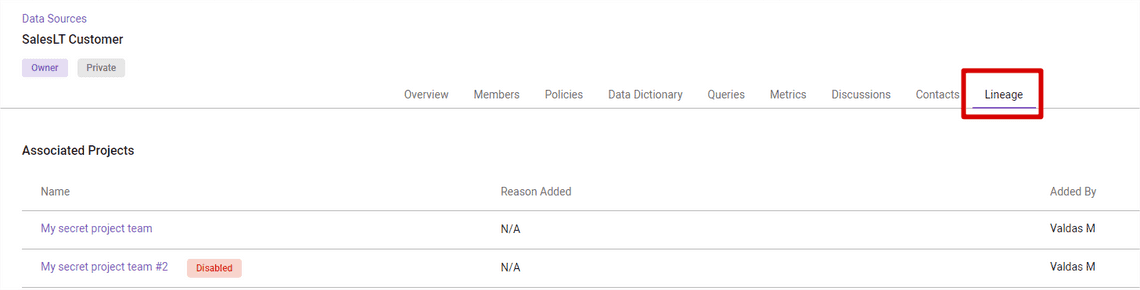
Public queries tab allows users to keep track of their personal queries, share their queries with others, and debug. Users can send a request for a query debug, which sends the query plan to the Data Owner. Interesting functionality, but haven’t tested it now.
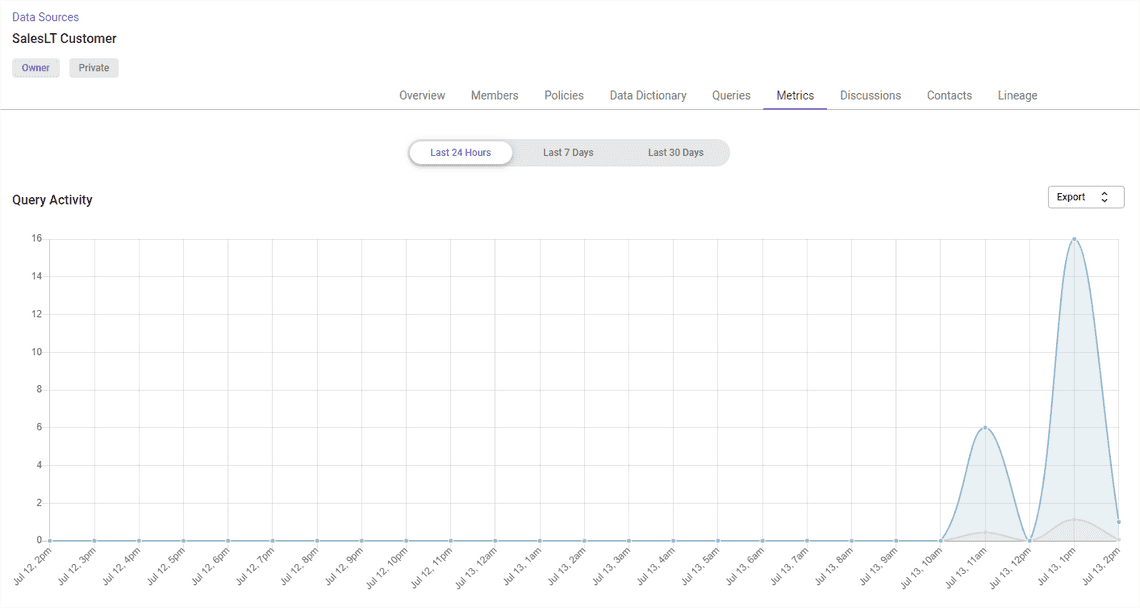
Metrics tab shows details about the data source usage and general statistics
Governance (tags, logs, reports, purposes)
Here is a section, that I as an engineer will not appreciate it enough. Immuta has powerful governance reports for data owners and data stewards, slicing and dicing access, sources, usage and other critical metrics to be compliant.
View per user
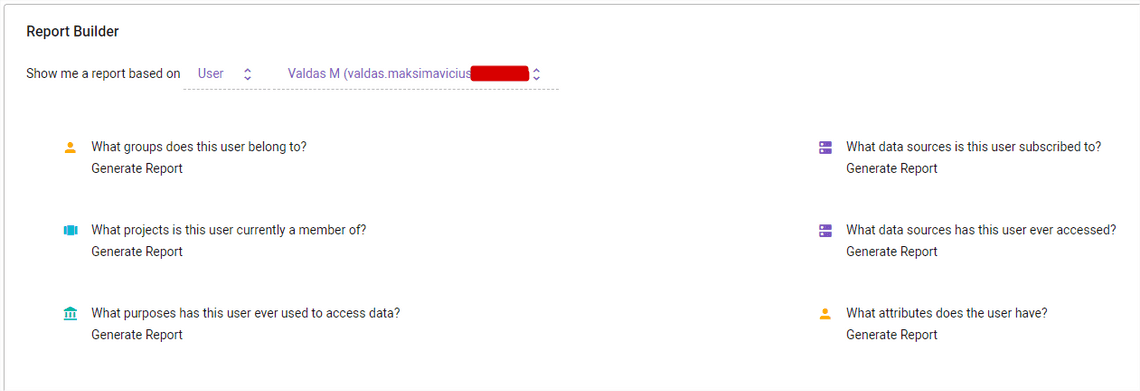
View per sources

View per project
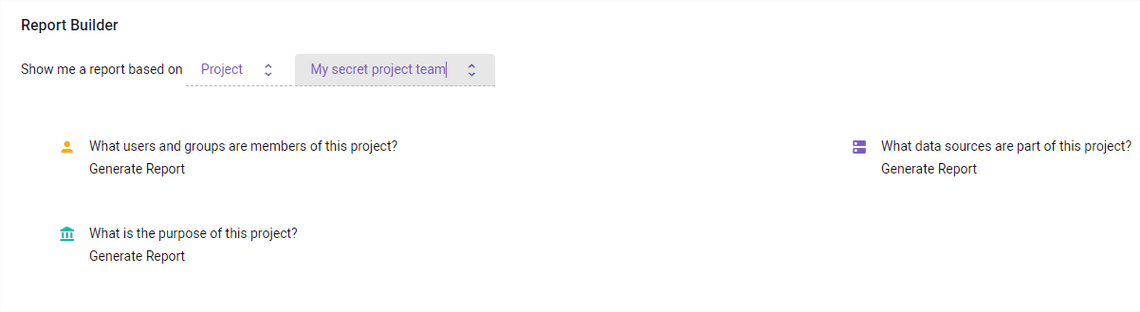
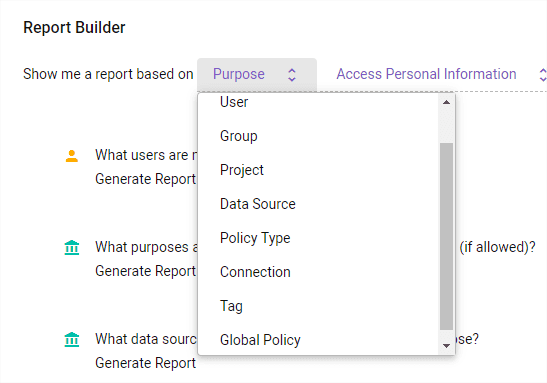
Other views
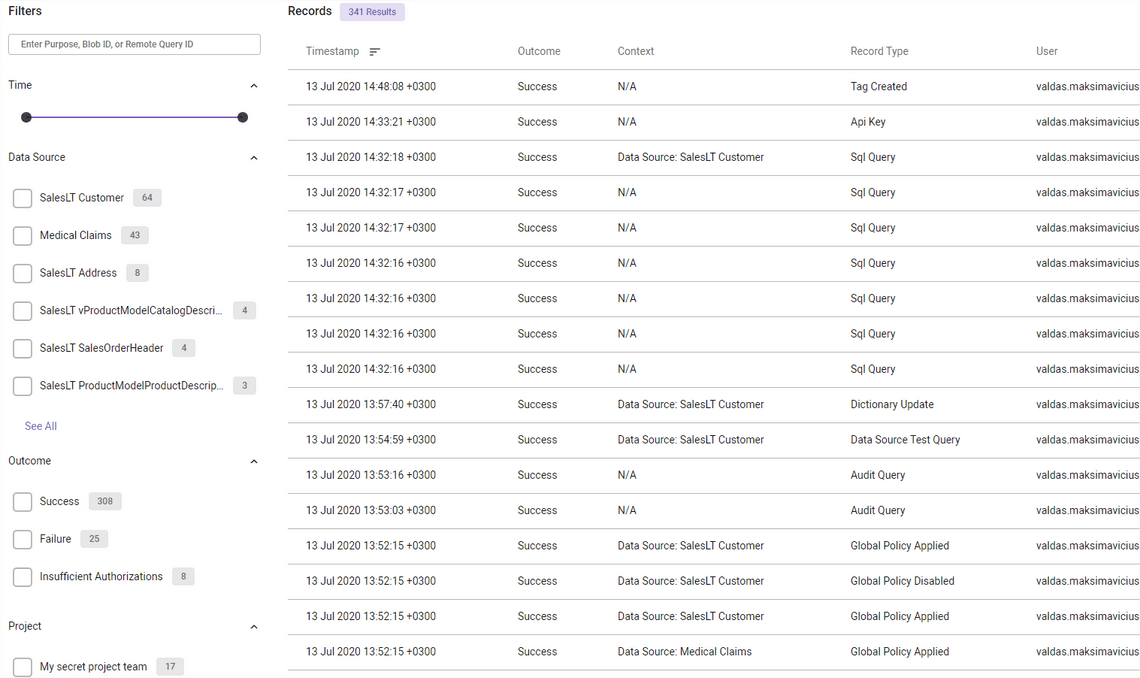
As well granular audit information.
Also, there are predefined tags and possibility to add your own tags (parent child hierarchy).
By creating data usage purposes, we can limit data access just to specific data usage scenarios.
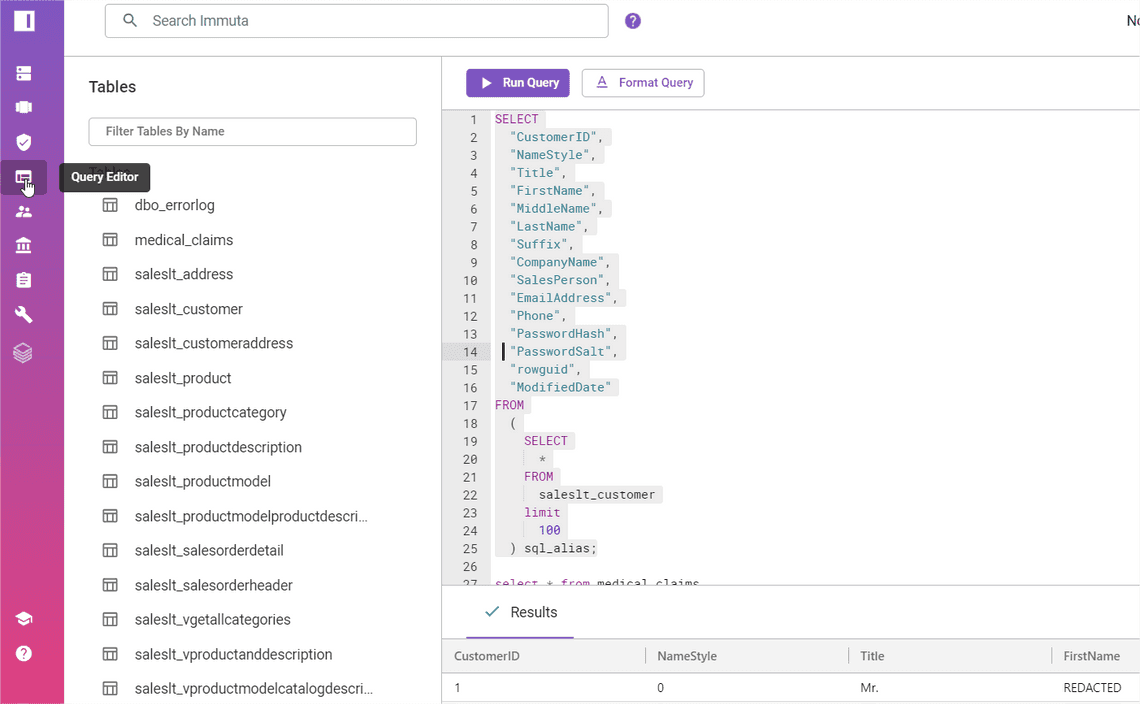
Query editor
There is a query editor, that got me thinking of underlying computation. In my case, I’ve connected Azure SQL database. Does it work with Data Lake Storage and what computation does it use then? What are hardware requirements? Unfortunately, I can’t test it properly as ADLS or other similar storages are to allowed in my trial version.
For me, the query editor is a functionality for data owners and source admins, rather than analysts. Analysts will be using other tools they like, e.g. Databricks, PowerBI. This query editor seems like a good place to check your policies, see data quickly. Debug user queries if needed.
Connecting with PowerBI
Here is where things start to get interesting. To access Immuta from PowerBI, I am asked to install PostgreSQL connector.
Later, I need to enter SQL credentials, which I can create on my profile page in Immuta.
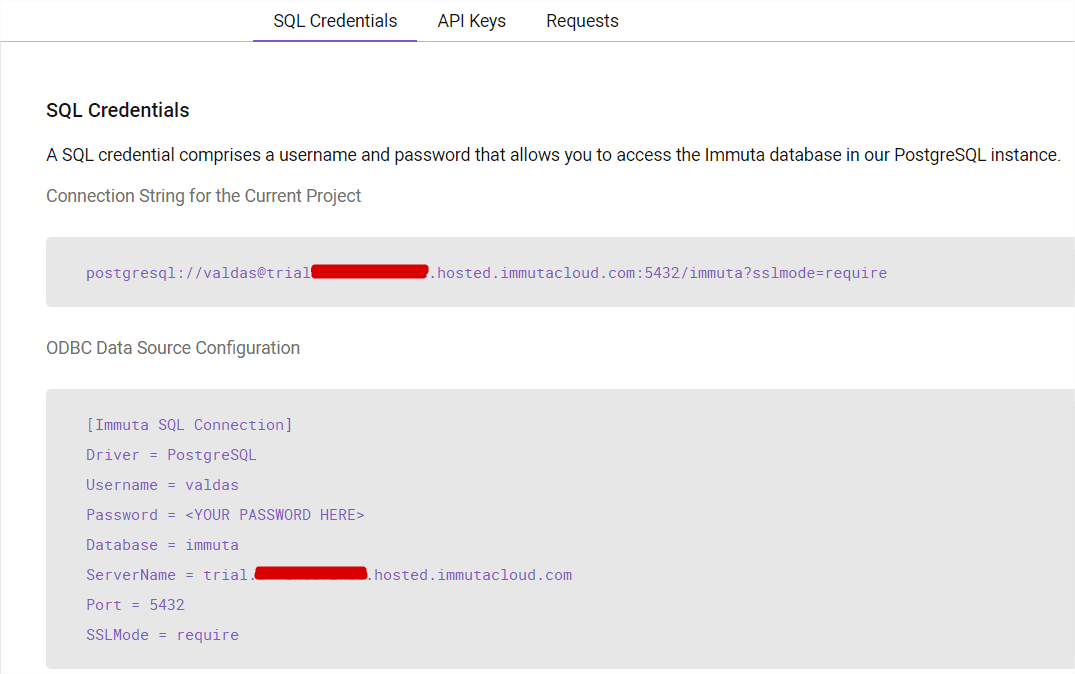
And eventually I receive connection strings with host and port information. This connection can be used not only from PowerBI, but as well any other reader supporting ODBC (with PostgreSQL drivers installed).
More about setting up PowerBI and enterprise gateway:
How does Immuta work?
What is now obvious to me, Immuta is not a data virtualization technology. It’s seems to be a data governance wrapper between sources and computation engines. Based on Immuta’s documentation, I see 6 different data access patterns (it seems each pattern uses different data retrieval and authentication strategy, definitions taken from Immuta’s documentation):
1. Databricks
Data sources exposed via Immuta are available as tables in a Databricks cluster. Users can then query these data sources through their notebooks. Like other integrations, policies are applied to the plan that Spark builds for a user’s query and all data access is native.
2. Immuta Query Engine
Users get a basic Immuta PostgreSQL connection (that explains PostgreSQL driver installation). The tables within this connection represent all the connected data across your organization. Those tables, however, are virtual tables, completely empty until a query is run. At query time, the SQL is proxied through the virtual Immuta table down to the native database while enforcing the policy automatically. The Immuta SQL connection can be used within any tool supporting ODBC connections.
3. HDFS
HDFS is least interesting for me. Immuta HDFS layer can only act on data stored in HDFS. There are certain limitation with regards to HDFS deployments and accessibility of other Immuta data layers.
4. S3
Immuta supports an S3-style REST API, which allows users to communicate with Immuta the same way they would with S3.
5. Snowflake
Native Snowflake workspaces allow users to access protected data directly in Snowflake without having to go through the Immuta Query Engine. Within these workspaces, users can interact directly with Snowflake secure views, create derived data sources, and collaborate with other project members at a common access level. Because these derived data sources will inherit all appropriate policies, that data can then be shared outside the project.
6. SparkSQL
Users are able to access subscribed data sources within their Spark Jobs by utilizing Spark SQL with the ImmutaContext class. All tables are virtual and are not populated until a query is materialized. When a query is materialized, data from metastore backed data sources, such as Hive and Impala, will be accessed using standard Spark libraries to access the data in the underlying files stored in HDFS. All other data source types will access data using the Query Engine which will proxy the query to the native database technology. Policies for each data source will be enforced automatically.
More about data access patterns
Installation
I have used a trial instance of Immuta’s managed installation. Based on documentation, I see Kubernetes option available which will satisfy most Enterprise needs. As well Immuta on AWS has Managed Cloud deployment. Can’t wait to see Azure managed cloud deployment.
More about installation options
My observations
Strong points
- Quick to get started with Databricks
- It provides one data access layer (tracks data health, access management, etc.)
- Advanced global and dataset policy management scenarios
- Advanced data governance reports and detailed audit information
- Native data collaboration features (dictionary, discussions, search)
- Smooth UI experience (except some glitches with data sources)
- If used just with Databricks, there is a DBU consumption based pricing model
Considerations
- No Azure managed cloud offering / Not available in Azure marketplace yet
- All access would be provided via Immuta, but it’s not quite a full data virtualization platform: no support for any kind of caching like Databricks Delta or Dremio, Synapse.
- No semantic model and virtual datasets creation. Immuta gives access to what you have already built elsewhere.
- It uses different data proxying techniques for different sources. Cross-source (using different patterns) performance and accessibility should be tested more thoroughly.
- Azure Data Lake Gen 2 not supported in the trial. Overall, it seems computational engine is still needed to access ADLS Gen 2 data. AWS has Athena, Azure has Synapse or Databricks.
- Licence based pricing model. Not as flexible as for Databricks.
- External data catalog might be still needed for an end-to-end view (lineage, cover sources outside Immuta, etc.).
Share


Related Posts
Other projects