What is Immuta and how does it improve data governance in Databricks? - Part 1


Today, we’ll learn about data governance enhancement tool for Databricks - Immuta. A few days ago I wrote an article, Introduction to Data Governance in Databricks, describing how to approach data governance in Databricks without buying additional components.
As there are many moving parts that require custom implementation, I decided to explore Immuta trial. Initially, I started this post as an Evernote message to myself. Eventually the note grew in length and I decided to share my steps and lessons learned with you.
The series of articles about Immuta is a part of my Azure Data Platform Landscape overview project.
- Part 1 - Getting Familiar and connecting to sources - Your are here
- Part 2 - Policies, catalog, my feedback
Get started
First, let’s sign up on https://www.immuta.com/try/ to get access to Immuta’s trial.
Secondly, I want to link Immuta with my own Databricks workspace.
The portal shows me a straight forward step-by-step tutorial of linking Immuta with Databricks. It takes less than 10 minutes to complete it. Major steps taken:
- Download Immuta Jar, which later has to be uploaded to our DBFS.
- Set up cluster init scripts to make sure that Jar gets executed during startup.
- Create Databricks secret and paste your unique Immuta account key
- Create a cluster policy (copy paste from Immuta)
- Create a Databricks cluster
- Execute your queries
Almost everything goes smooth, except the last step. I am not able to run queries. I get an error: NonImmutaUserAuthorized: Unable to create an API key (401: Unauthorized)

Reason? I didn’t read documentation and I chose two different users in Immuta and Databricks.
“It is important that the users’ principal names in Immuta match those in your Databricks Workspace. For instance, if you authenticate to Databricks with your.name@company.com, you will need to authenticate with Immuta using the same username.”*
After solving my user issue, I get another error related to disabled JDBC. It seems it’s related with the cluster policies I’ve created earlier.

Adding “SET immuta.enable.jdbc=true;” solves the issue. Now I can see medical_claim data from Immuta (the source available as demo data).
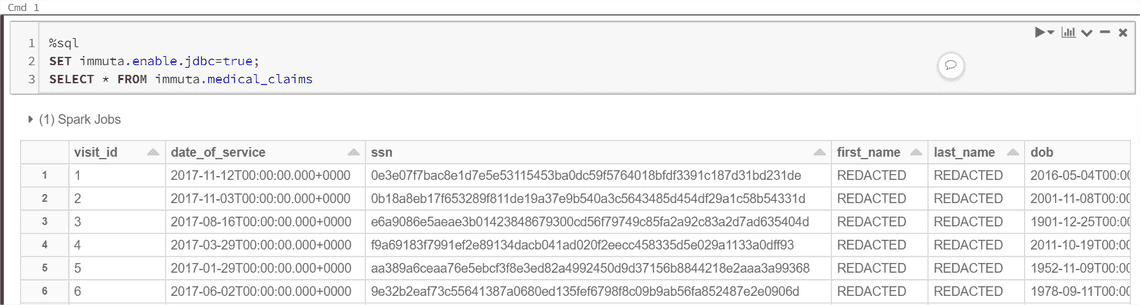
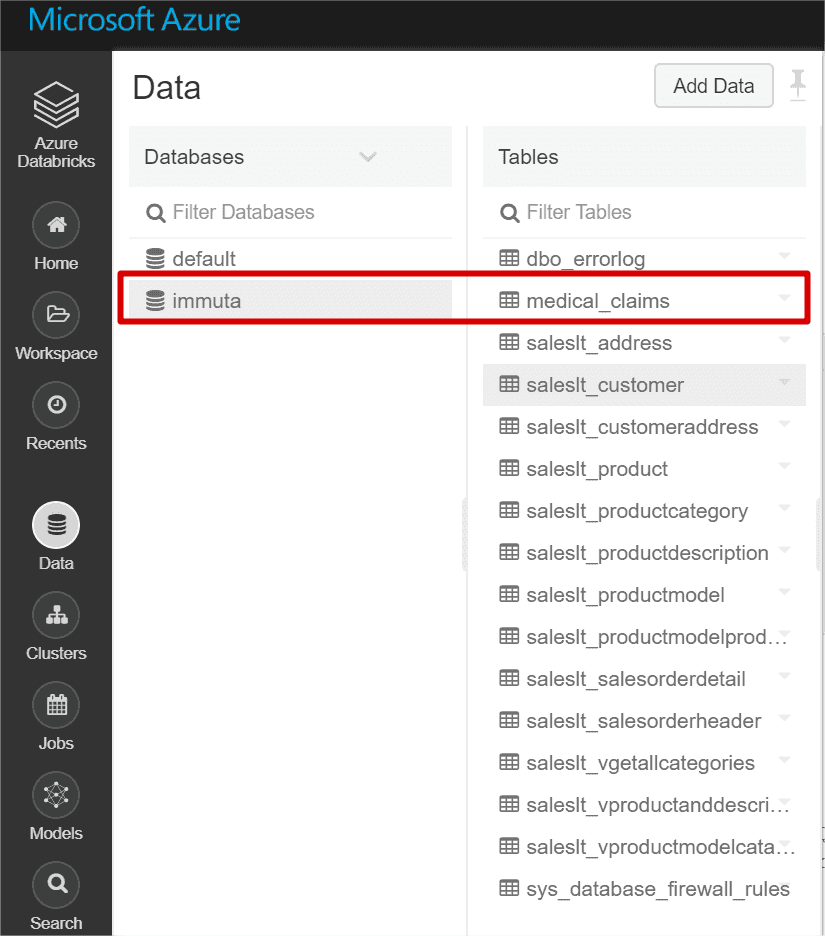
And here is another view of how Metastore database and tables look like in Databricks. We see Immuta database and medical_claims table. ( We see other tables too, because I took the below print screen after connecting other sources)
Add data sources
Great, what’s next? I want to connect a few other sources and see how it works with Azure Data Lake Gen 2, SQL databases.
I see quite a few connectors, but I miss Azure Data Lake Gen 2. Only after visiting the Settings I get a dissapointing message:

Anyways, we have to live without it now…. In that case, let’s try to connect to my Azure SQL instance. After playing with Immuta for half an hour, UI feels modern and friendly. Tips and pop ups help understand the tool even faster.
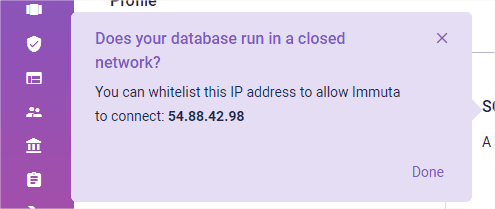
In the example below, the popup proactively reminds me about whitelisting an IP address to allow Immuta connect to my database. The trial version of Immuta runs on their infrastructure, but for enterprise deployments, you will have a possibility to deploy it within your virtual network. But about that later.
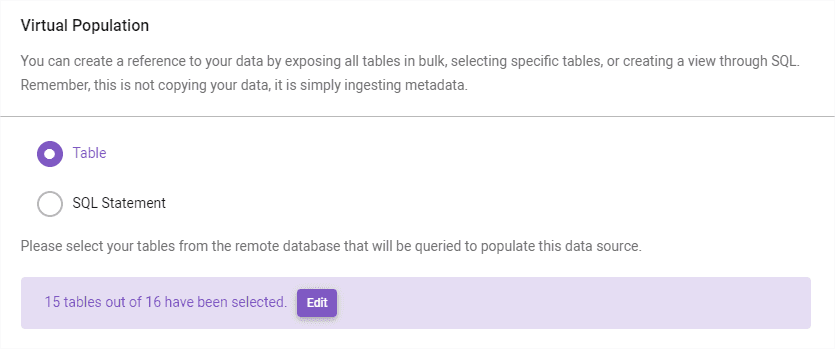
Once the connection succeeds, I get a message asking what metadata I want to ingest. The message emphasizes metadata ingestion, nothing related to data copying. I decide to allow Immuta fetch 15 out of 16 tables.
Later, there is an interesting Advanced section. I go with default settings, without investigating much different settings.
After clicking Create, my data source gets connected and tables become visible in the Data Sources tab.
Query data
Let’s open Customer table. The table view has new tabs: members, policies, data dictionary, queries, etc. I am going to explore that later.
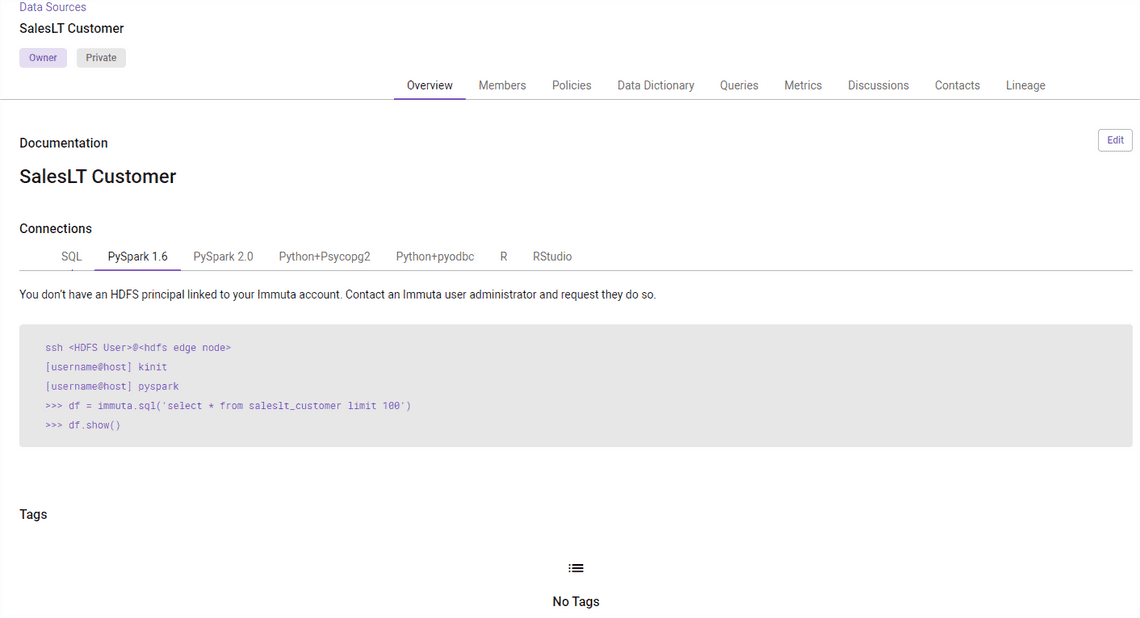
Now, I am interested in reading the table I linked earlier in Databricks. According to description, it should be
SELECT * FROM saleslt_customer limit 100
However, the Metastore database name in Databricks Metastore is “Immuta”. We have to add it as a prefix. Let’s try.

Something fails: “Reference to database and/or server name in ‘adventure-works-db.SalesLT.Customer’ is not supported in this version of SQL Server.” What? It sounds like a SQL Server driver issues…
Interestingly, Immuta shows data health issues in its UI. Good idea to show that in one and central place right after any client faces issues.

I can even run tests and look for possible fixes.
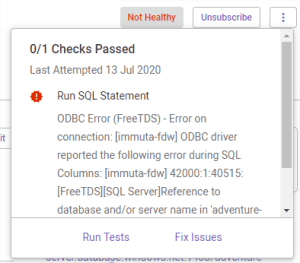
Unfortunately, the issue still persists. Quick googling says that referencing full table name, like “SELECT * FROM [Database.B].[dbo].[MyTable]”, appears to be not allowed in SQL Azure. So it’s Azure SQL issue, not Immuta’s.
As this is only demo and I want to get things working ASAP, I decide to use my SQL statement instead of Immuta’s. I assume there is a better solution for this, bet let’s hack a bit now.
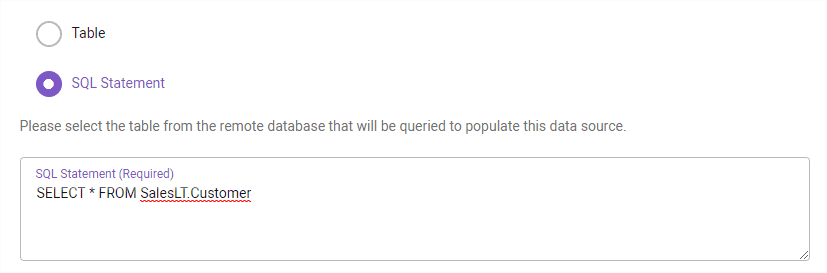
Ladies and gentlemen, we have lift off! My SQL table query goes via Immuta and I see results in Databricks!
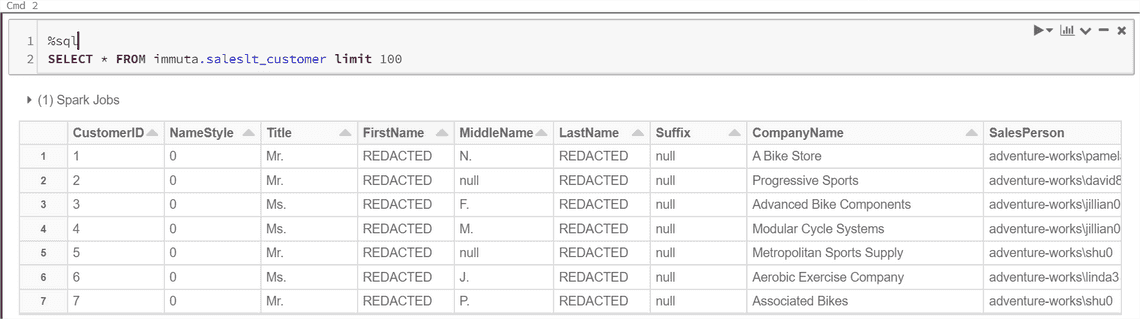
Hey, wait a minute! Why First Name and Last Name is replaced with a static value - REDACTED? The SQL query is proxied through the virtual Immuta table down to the Azure SQL database while enforcing the policies. It applies policies on the fly. AWESOME!
Create data policies
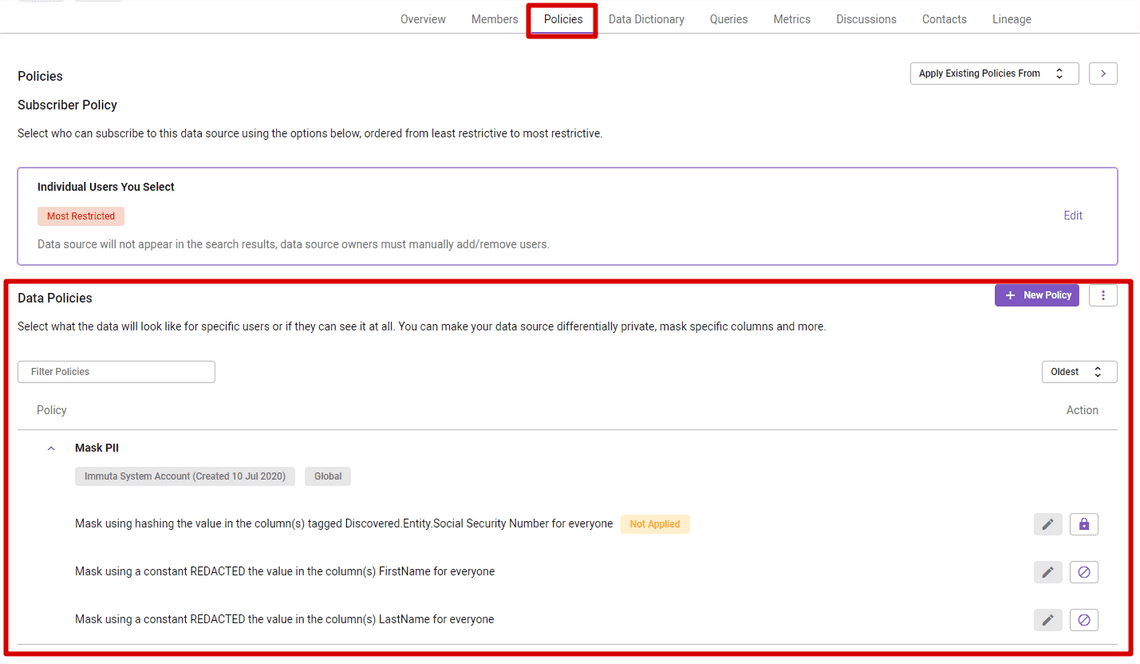
Why am I not allowed to see FirstName and LastName columns? After visiting Policy tab inside the table view, I realize there is a global policy named “Mask PII”. It picked up my schema automatically, and decided to hide these columns based on predefined patterns.
After connecting to my Azure SQL database, Immuta posted the below notification. It makes more sense now.
Global polices are managed on the Immuta subscription level. That’s a great functionality to ensure sensitive information is not leaked by an accident. Better to hide it globally by default than be sorry later.
In addition to the global “Mask PII” policy, I want to create a custom Customer table policy. As you can see below, we have quite a few actions available:
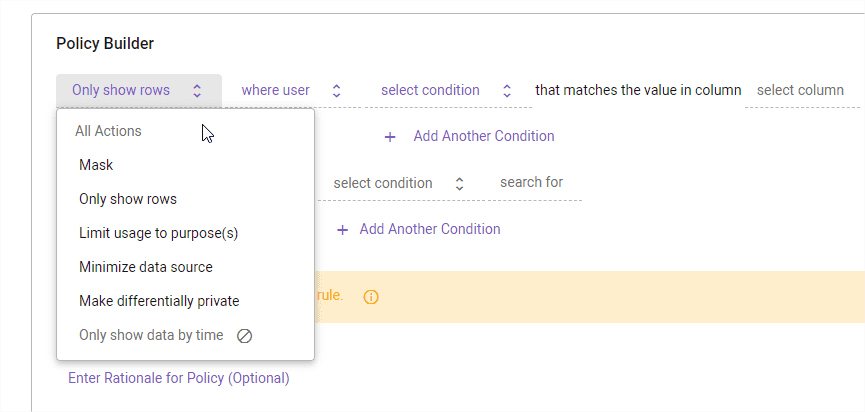
The policy builder has an impressive functionality. Based on user names, groups, LDAP attributes you can create foundational policies:
- Mask values - many options like hashing, replacing with constant, regex, rounding, K-Anonymization, format preserving masking
- Limit rows - row level security
There are as well some more advanced and interesting items, like:
- Limit usage to purpose - to access you need to be granted purpose privileges, e.g. claim analysis, medical health analysis, credit card transactions, etc.
- Minimize the amount data shown (e.g. top 100 for all tables just to get familiar with the schema)
- Make deferentially private - policies will only return results for a certain type of SQL query: aggregates, such as the COUNT and SUM functions.
Talking about data policies, it’s worth to mention a bit about subscriber policy. It defines how table access management.
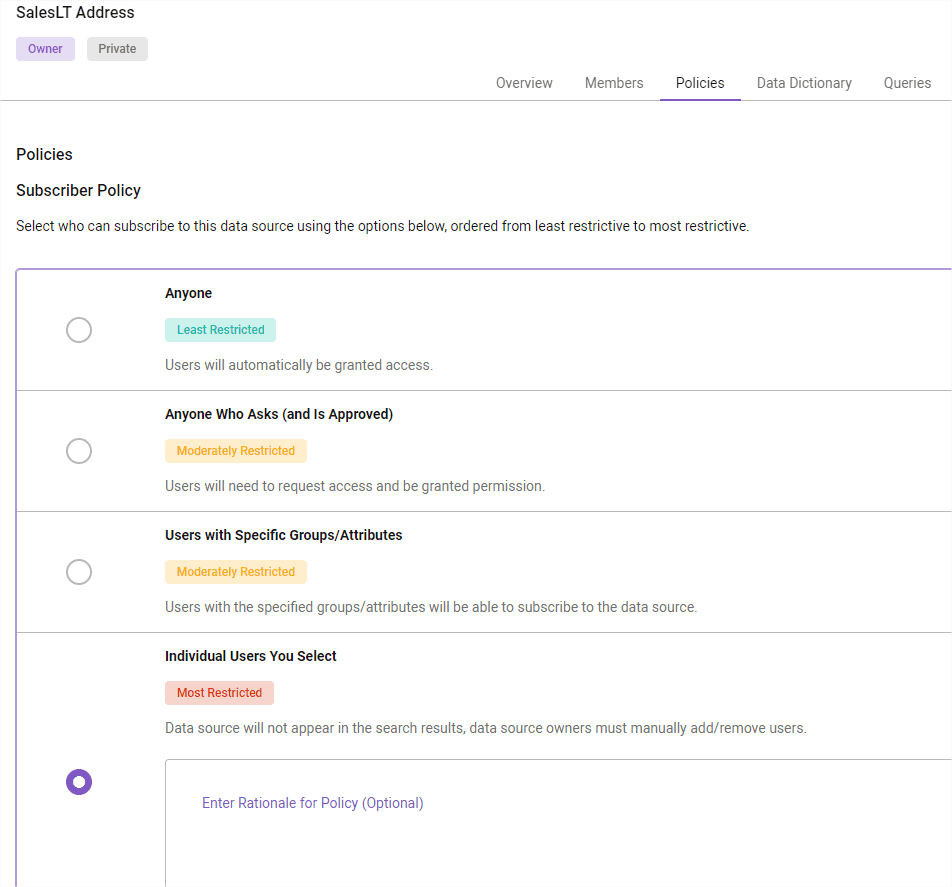
All my Azure SQL tables got “Most Restricted” access policy as these contain customer information. As you can read in the description, tables are not even visible in search and data source owners must manually add/remove users based on rationale.
There are weaker options available. If you are a part of specific group, then all members get access to it. Another option is to ask for permission, and data owner gets notification to approve/deny access.
Or, if a dataset contains no sensitive information (like general statistics), then you can select Anyone and make it public.
You can read more about access and row-level policies
Projects and purpose-based policies
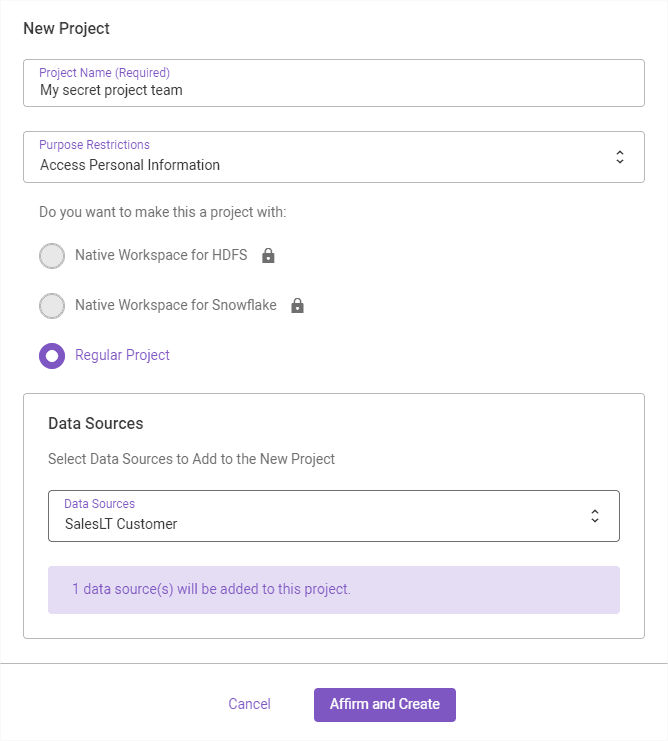
Let’s create a secret project. The idea here is to group members via a project to better control data usage. And clearly link with purpose restrictions.
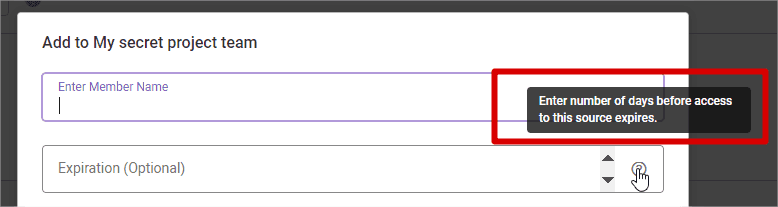
Later, let’s add members and specify time-bound access. Brilliant functionality!
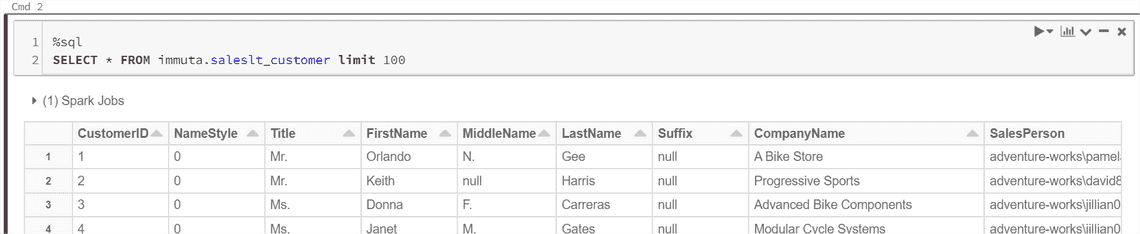
And now, as a member of a secret project working with a purpose, I can view all the columns.
Interim summary
This article kicked things off with Immuta. We connected to a data source and observed data policies in action.
In Part 2, I dive into more details. Check it out!
Share


Related Posts
Other projects