



Data Governance From an Engineering Perspective
August 06, 2020
2 min
There are many metadata management tools and solutions. Some specialize in data discovery, search, lineage, others in business processes. Which data management tool is the best? What features are must-have and nice-to-have in a data catalog? In this blog post
This post is a part of Data Governance From an Engineering Perspective, a series of posts about Data Governance and Metadata.
It’s about time to give you more details and present available solutions. As there are many different tools with unique approaches - I decided to call it The Data Management Zoo.
If you haven’t been under a rock, you might have heard of data catalogs or business glossaries.

I am overwhelmed by the sheer number of available tools and differences between them. Some of the questions I have:
There are so many questions and so little answers…
In the latest Gartner’s reports, you find metadata management tools split into standalone and embedded tools.
Such separation makes sense. Yet, I would add one more option. Based on my experience and inputs from my readers, many decide to build custom solutions.
1. Standalone tools
Some solutions provide “complete” data governance and metadata management.
Open source community has two big projects:
Considerations: The standalone tools are as powerful as their crawlers and connectors. Also, integration into your data ecosystem and business processes is not straight forward.
2. Embedded tools
Increased customer interest in metadata makes it a lucrative market for vendors. New projects appear. As a result, data platform components include metadata management as a feature.
For example (tools with built-in metadata features):
Considerations: To achieve end-to-end governance, all data has to “flow through” embedded solutions. As a result, you might use the tools in the wider scope than you planned and increase lock-in. Otherwise, you end up with metadata silos.
3. Custom implementation
Consideration: As always with custom implementation, you might end up reinventing the wheel.
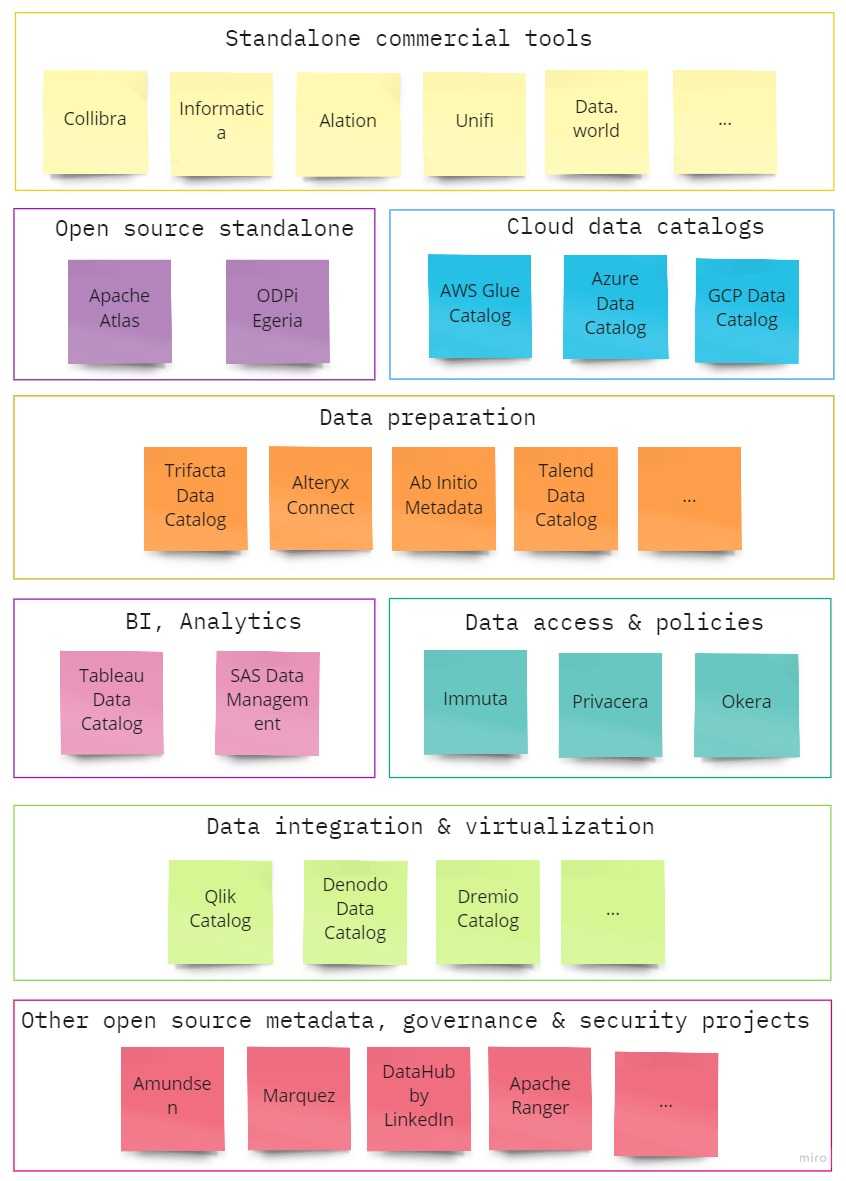
I see way to often consultants recommending big and standalone solutions by default. Also, all open-source metadata projects end up under the rug.
I don’t agree with such approach for three reasons:
Instead of deconstructing which metadata tool is best, build your own MVP.

Source: https://github.com/danistefanovic/build-your-own-x
Štefan Urbánek, a former Facebook engineer, gave a talk about about the importance of metadata and architecture.
He presented the following approach:
1. Pick a metadata problem
2. Use a spreadsheet (users already have Excel or Google Sheets)
3. Suffer through the document-exchange phase
4. Use functional approach to metadata composition and application
99. (later) Move spreadsheets into a metadata repository
“We’ve used_ Marquez as a starting point and easily extended it to fit our needs such as enforcing security policies as well as changes to its domain language. If you’re looking for a small and simple tool to bootstrap […] Marquez is a good place to start.” - ThoughtWorks Technology Radar Vol.22
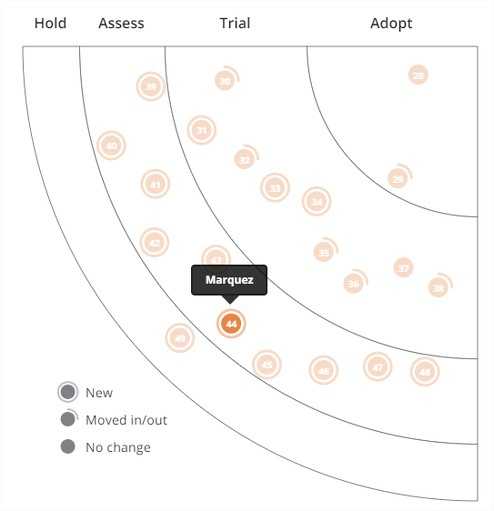
Source: https://www.thoughtworks.com/radar/platforms/marquez
First, Marquez is a fresh, platform-agnostic open source project led by Julien Le Dem. Julien is one of the “Big Data” landscape shapers. He coauthored Apache Parquet, contributed to Apache Arrow.
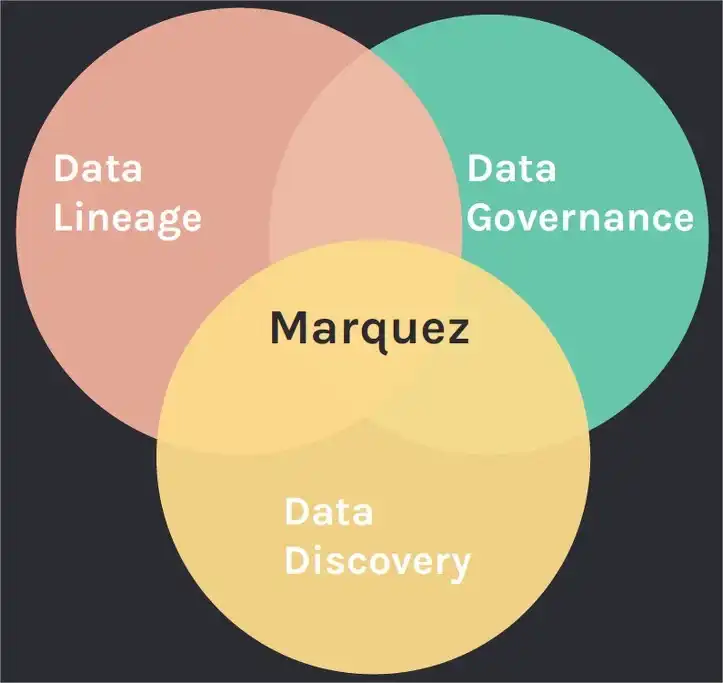
Marquez is still in early development stages. So running it in production might be risky.
Instead, look at the project as an educational journey. Figure out what you need, what is missing. Then decide on next steps, or even switch to the commercial tools.
There are many metadata management tools and solutions. Some specialize in data discovery, search, lineage, others in business processes.
What makes me mad as an engineer, is the difficulty to test and explore some commercial tools. You have to reach out to sales reps to get access, instead of pulling a docker image and running it.
If you want to start small and learn as you go, give open-source tools a chance. Take a look at Marquez. It is a rather small, but powerful metadata management project. Use it as a starting point. Or look at some other alternatives, like Amundsen or DataHub.
Other projects