



Data Platform Mastermind
September 05, 2021
2 min
Metadata is simply data about data. It is a description and context. In my opinion, metadata is as important as the actual contents. How can you possibly trust the contents if you don’t know who collected it, how and why?
This post is a part of Data Governance From an Engineering Perspective, a series of posts about Data Governance and Metadata.
We are here:
We collect more data than earlier. No doubt about that. A wide range of tools allow us to capture, store and analyze items that 20 years ago were not considered (documents, videos, pictures, sound). Yet, how accurate the data is?
Have you ever wondered what is the difference between the fact and the stored data?
How does a transaction or a customer profile differ from the reality?
Instead of getting into philosophical discussions, let me say it straight away - we need context for data to be meaningful.

Source: https://www.memecenter.com/
You can see context as data’s ecosystem. A common vocabulary and a set of relationships between components. The more we know about that ecosystem, the better we can interpret the data within it.
For example, you have a low-grade fever - 37.3 C. There is a chance you got a cold virus and you should rest
Provided you met a COVID-19 infected person a few days earlier changes the context. You have to isolate yourself now.
Another example - troubleshooting the infamous blue screen of death.
Source: https://www.flickr.com/photos/9704498@N05/3383841393/
By looking at the error message you won’t solve the problem. To find out the root cause of the error, you want to look into:
Gathering surrounding data and making a timeline of events shows potential causes. The more context and metadata you get, the more meaning you extract.
Metadata is data about data. It is a description and context.
Metadata is as important as the actual contents. How can you trust the contents if you don’t know who collected it, how and why?
Look at a sales table below:
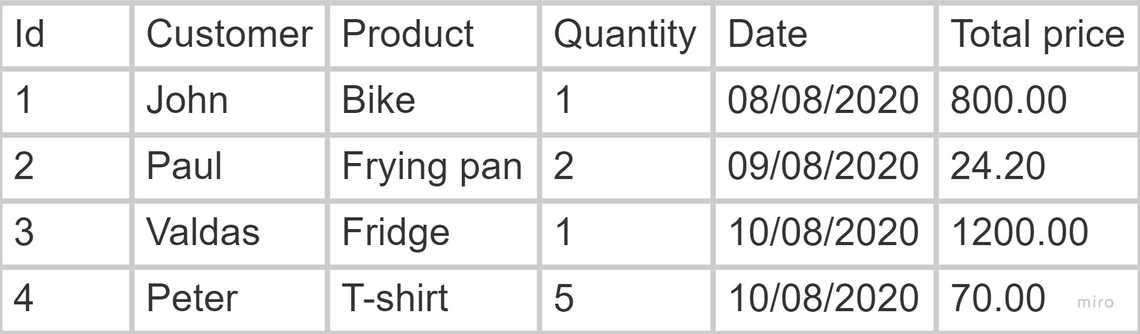
We know the answers to some of the questions:
While other questions are impossible to answer:
Assume there is a system table with data types and descriptions.
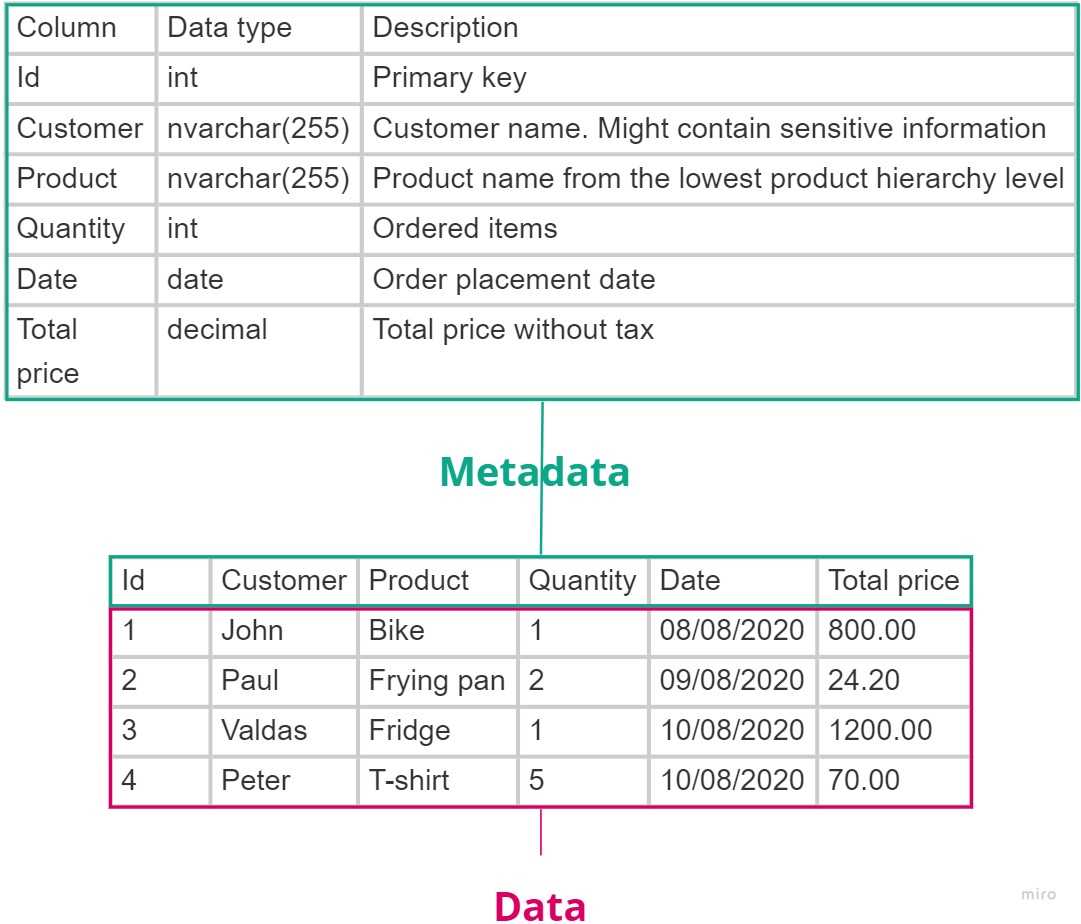
Now, we know a bit more about our sales table:
Next, assume there is table level information.
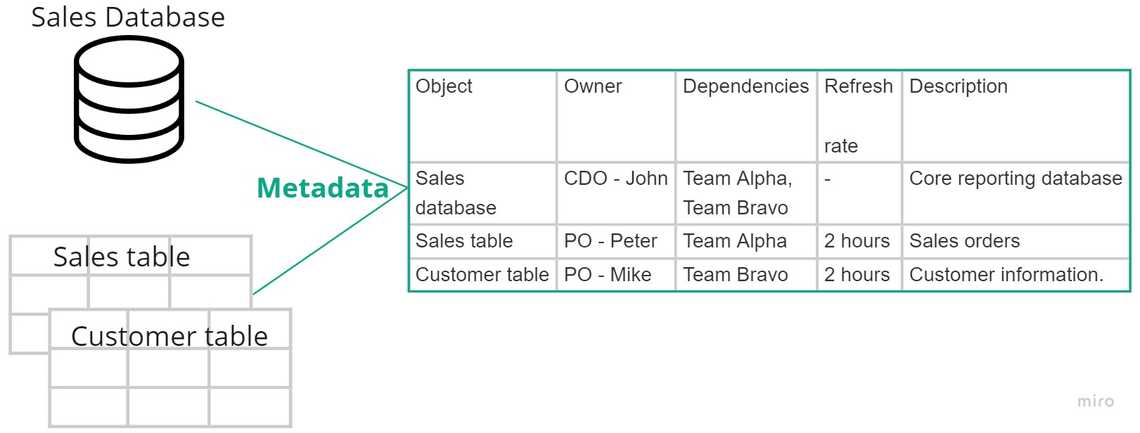
How to put it place?
Suppose we use Azure SQL or SQL Server as our database. Both have a useful feature called “Extended properties”.
Extended Properties allow to store more information about database objects. Imagine this as comments on:
For now, remember that each row in your business table has hidden data:

Check out for more examples on: https://dataedo.com/kb/data-glossary/what-is-metadata
As I mentioned earlier, the more context and metadata you get, the more meaning you extract.
Storing all the surrounding data has drawbacks too:
Also, as the series focus on an engineering perspective, here a few technical concerns:
“To understand recursion metadata, you must first understand recursion metadata!”
Other projects