



Data Platform Mastermind
September 05, 2021
2 min
In this blog post, we will look at data models, differences between fixed and flexible schema, role of data structures. Data models describe how a user interacts with the data. It is an abstraction layer, or to be more precise - a set of layers. In simpler words, it’s a plan or outline for an end-user how to understand data.
This post is a part of Data Governance From an Engineering Perspective, a series of posts about Data Governance and Metadata.
The contents of this post might make more sense if you read the previous posts in this series.
Data models increase data understanding across systems and processes. They provide definitions, ensure usage rightfulness
Without data models, you end up with inconsistent, ambiguous, incorrectly classified data silos.
However, there are more than one data model definition. Here’s my take on it.
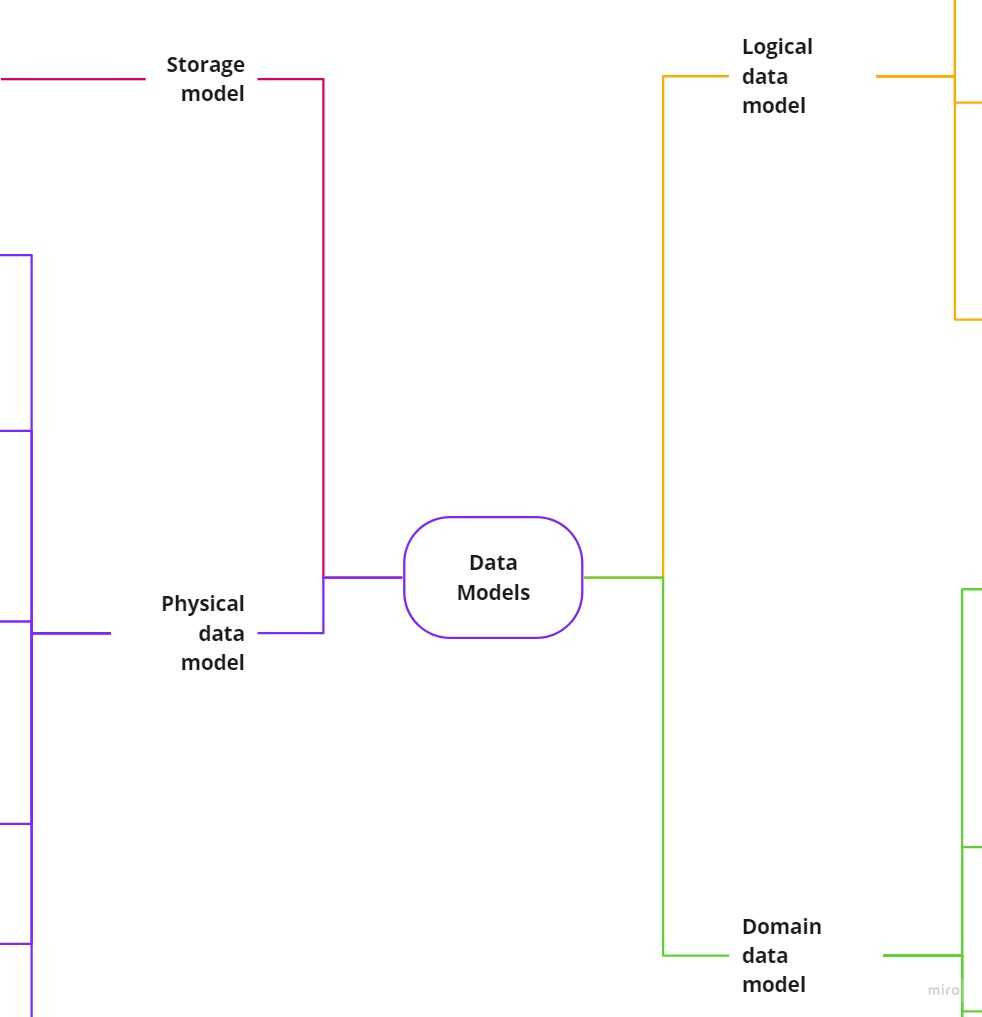
Data models describe how a user interacts with the data. It is an abstraction layer, or to be more precise - a set of layers. In simpler words, it’s a plan or outline for an end-user how to understand data.
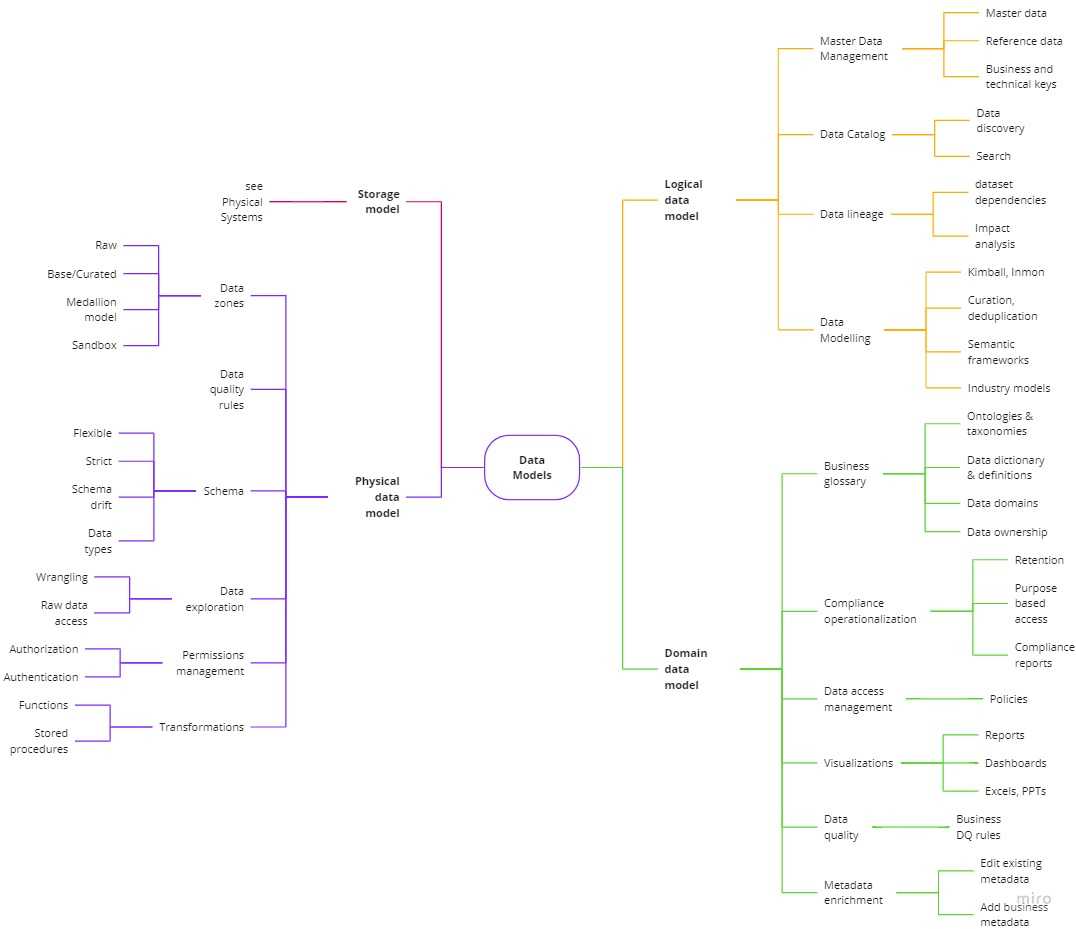
There are 4 layers we should be aware of:
”[…] storage model, which describes how the database stores and manipulates the data internally. In
an ideal world, we should be ignorant of the storage model, but in practice we need at least some
inkling of it—primarily to achieve decent performance.”_ - NoSQL Distilled, 2012
The second layer, a physical data model, describes storage and database artifacts: tables, columns, keys, data types, validation rules, database triggers, stored procedures, domains, and access constraints,
Logical data model helps in building data semantics, meaningful data aggregations. It includes modelling frameworks, entities (tables), attributes (columns/fields) and relationships (keys).
Last but not least, domain data model, uses non-technical and business terms. It defines business processes & behavior. Doesn’t contain technical implementation details.
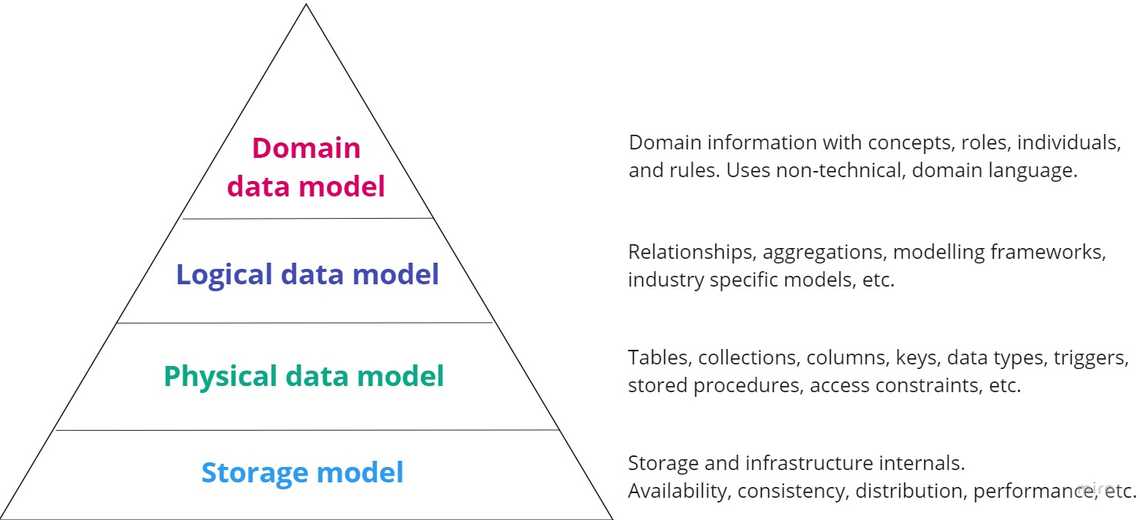
The lowest abstraction layer, the storage model, describes how databases manipulate data internally.
Databases use different techniques and algorithms, offer different availability, consistency, performance capabilities. It’s important to understand these limitations during the technology selection process.
What data structures data storages use?
Greg Kemnitz, one of the Postgres contributors, nicely summarized on Quora - “databases use pretty much every data structure you’ve ever heard about - and many you probably haven’t encountered”
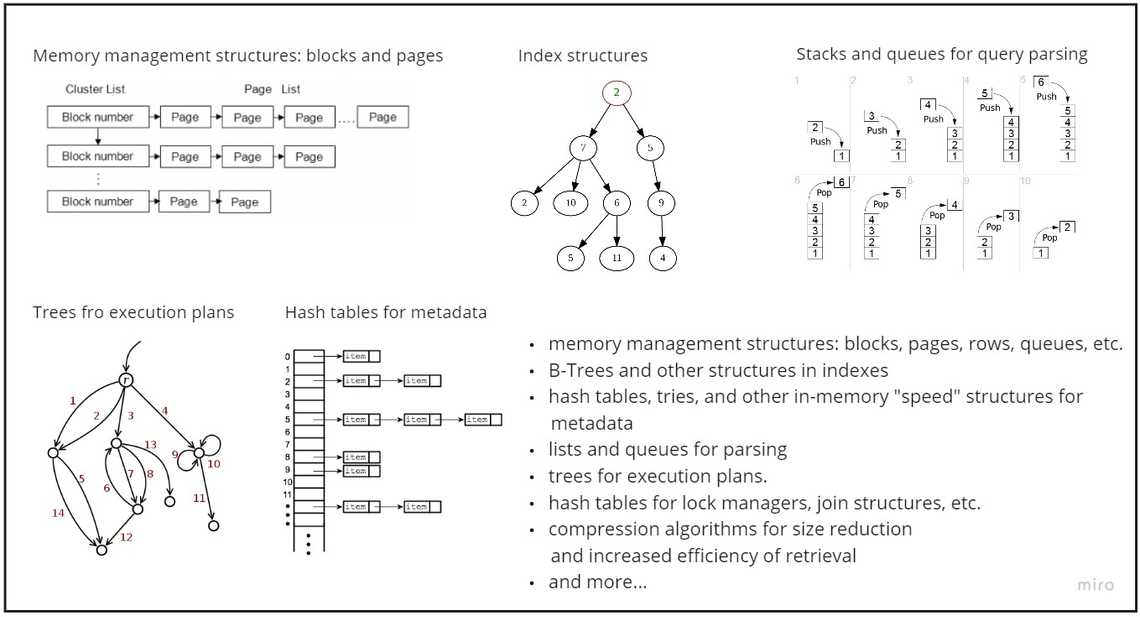
As Greg pointed out in his response, the vast majority of data structures in a database don’t store data. “They’re for parsing, query optimization, query execution, concurrency, query scheduling, managing application connections, etc.”
How is the storage model relevant to data governance?
There are certain trade-offs you have to be aware:
If you are interested more into understanding different storage models, database internals, build your own storage and learn by doing.
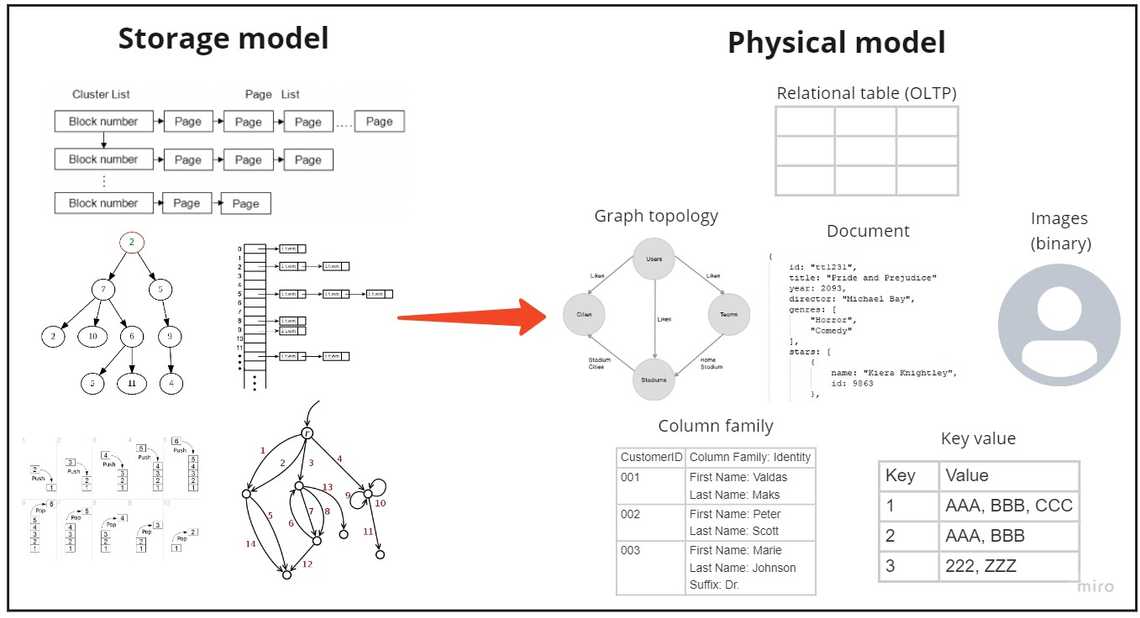
There is no need for us to dive further into data structures, algorithm performance. Instead, let’s jump up the abstraction ladder and look into the physical model.
Here’s where we start talking about data contents. The physical data model acts as an abstraction on top of our storage model. You can see it as a user friendly UI on top of complex data storage model.
We can use various building blocks to establish our physical data model:
One of the most popular and widely use physical data model is the relational data model. It is best visualized as a set of tables, rather like a page of a spreadsheet. Each table has rows, with each row representing an entity. We describe this entity through columns, each having a single
value. A column may refer to another row in the same or different table, which constitutes a
relationship between those entities.
An alternative to the relational model is NoSQL world. There are four main categories with different physical data models: key-value, document, column-family, and graph.
Flexible vs. predefined data model
Physical data model is the definition, the database schema the implementation. Some implementations have flexible, other have strict schemas.
Schema is a representation, manifestation of physical data model.

Everyone exposed to music, video or graphics editing is familiar with compression. Basically, you want to find a sweet spot between quality and size.
For the best results, you choose lossless compression - it allows the original data to be perfectly reconstructed from the compressed data. For example, it is used in the ZIP file formats.
With data and analytics, there is a concept of raw data. Data in it’s native format, not cleaned, or aggregated, with history. Data products built on top of the raw data, can be recreated if needed (just like the lossless compression).
Before the rise of cloud storages and NoSql databases, the capability to store raw data was limited. Relational databases, for instance SQL Server, MySQL or PostgreSQL, required a predetermined schema, pre**defined physical model.**
Here is a person’s table definition example:

Downsides of the predefined schema approach (also called schema-on-write):

Data, just like the shape toys above, takes on different shapes. New storage technologies reduce cost per GB, allow to store more data in its native, raw, format.
Schema-on-read is dramatically simpler up front - you don’t have to force your data through a predefined schema.
Schema-on-read means you can write your data first and then figure how you want to organize it later. What are the benefits of schema-on-read?

Source: https://redbullracing.redbull.com/video/mystery-box-mayhem
Apart of the advantages discussed earlier, there are some drawbacks to schema-on-read too:
Read more about NoSQL databases https://pandorafms.com/blog/no…
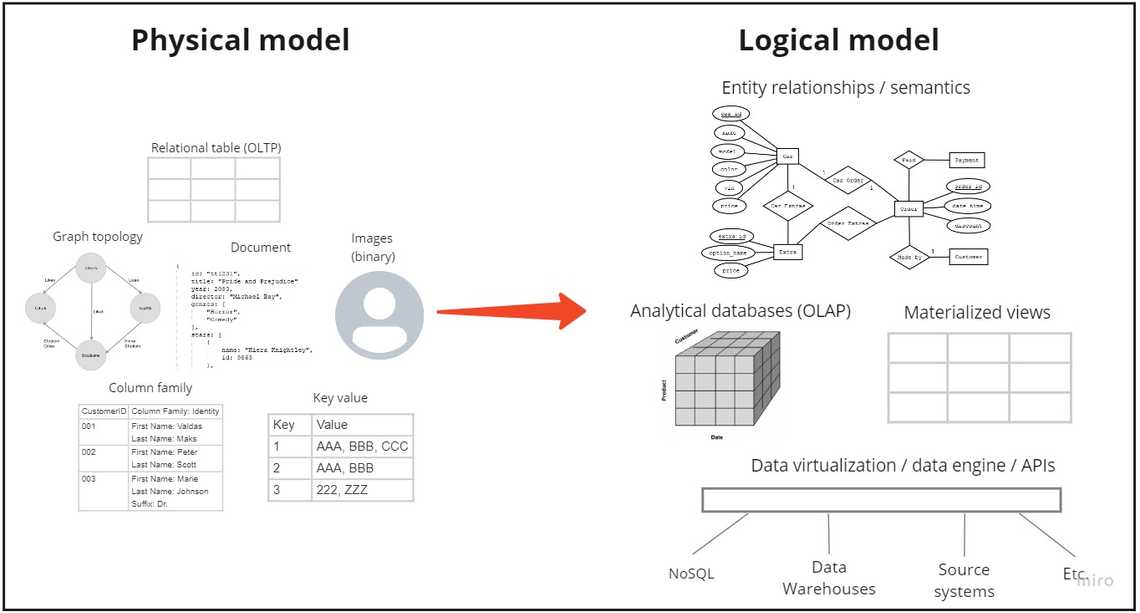
We have a physical data model - tables, documents, graphs. We want to start building logical groupings of data along with business rules. We will be grouping data into data entities, setting up relationships. Disparate tables and technical column names start getting user friendly and business specific shape.
What is the main difference between the logical and physical data models? The logical data model does not care about the underlying storage technologies. We want to build semantics, aggregations, meaning datasets. In theory, we shouldn’t care either our data is in SQL, NoSQL or binary files.
Talking about logical data modelling, I need to mention data modelling techniques. You have Kimball, Inmon, Data Vault approaches. Tomas Peluritis wrote a brilliant piece on different modelling techniques - Guide to Data Warehousing.
In some cases, you might decide to purchase a data model instead of building one from scratch. Companies like IBM, data.world, ADRM software (part of Microsoft), and others, provide ready for use industry models.
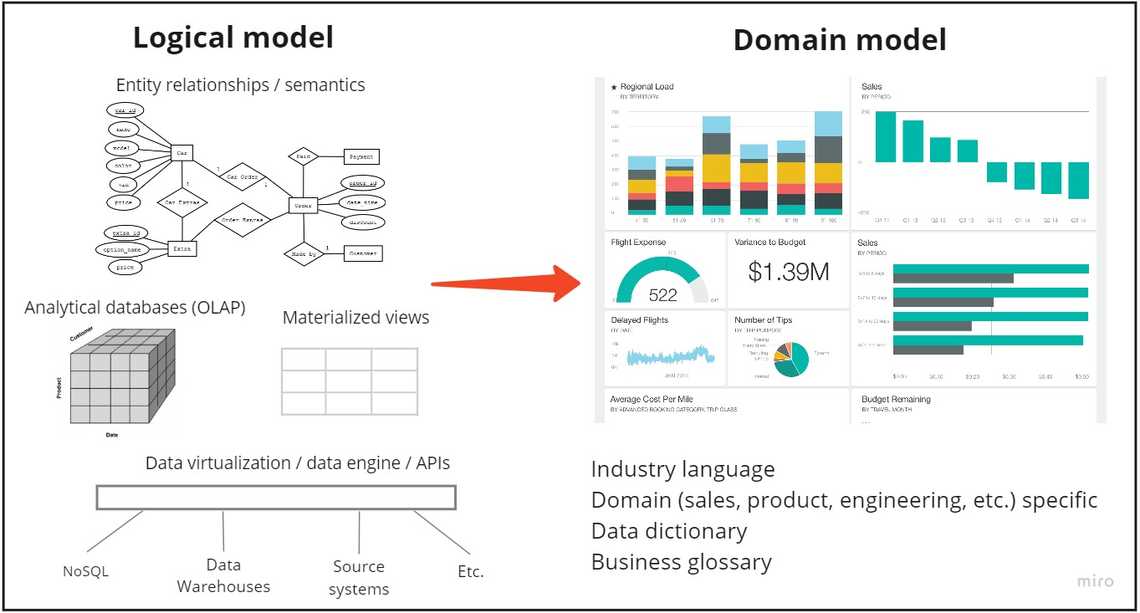
Thanks to logical data model we have relationships and unified data view. To achieve full data understanding across the organization and all stakeholders, you need to augment it with additional dictionary, business definitions, etc.
Without getting into the details, just look at how different English accents differ.

Source: One language, three accents
Similarly, you have to be aware of different customer, product definitions in your company’s data. It depends who is your data user and what objectives does one want to achieve with the data.
That’s where the domain data model is required. Not only specifying entity definitions, but also in some cases tweaking the logical data model. Either the consumer is sales department, user support, etc.
Storage, Physical, Logical and Domain models are just a part of a bigger picture.
Other projects